Edición de textos en COSUIZA/Teitok
En esta sección presentaremos una guía detallada de los procedimientos de edición en la página del COSUIZA. Este capítulo se divide en tres apartados. En el primero se hace una presentación de las etiquetas que componen la cabecera de todos los documentos del corpus y un repertorio de las etiquetas aplicables al texto. El segundo expone las posibilidades de automatización que ofrece Teitok en el proceso de edición. Finalmente, el tercer apartado, ofrece una serie de videotutoriales que exponen el proceso de creación y edición de un documento en la página del COSUIZA.
Guía de etiquetado
Cabecera
Como se ha indicado previamente, los metadatos se presentan dentro del elemento <teiHeader>. Esta sección puede ser muy sucinta o muy extensa dependiendo de los requerimientos del proyecto en el que se inscribe la edición. El <teiHeader> del COSUIZA recoge los datos necesarios según los criterios de la red CHARTA y las exigencias de TEI. Este elemento, que de ahora en adelante llamaremos cabecera se compone de cuatro elementos hijos que detallamos a continuación:
- <fileDesc>
- <encodingDesc>
- <profileDesc>
- <revisionDesc>
1. <fileDesc>
Contiene los elementos que proporcionan información bibliográfica del documento electrónico.
1.1 <titleStmt>
El enunciado de título ofrece la información relativa al título del documento electrónico y las personas u organismos responsables de su realización.
1.1.1 <title>
Todos los documentos del COSUIZA llevan por título una secuencia alfanumérica como se ilustra en el ejemplo debajo:
<title>COSUIZA-0001</title>1.1.2 <funder>
Ofrece la información sobre la institución o individuos que financian el proyecto. Para todos los documentos del COSUIZA el contenido de este elemento es el mismo:
<funder>Universidad de Lausana</funder>1.1.3 <respStmt>
El enunciado de responsabilidad provee información sobre las personas que han participado en la producción del documento electrónico, también se precisa el rol de cada una. Se deben distinguir tres roles de acuerdo a los criterios de edición CHARTA y uno específico a la producción del documento electrónico. Cada uno de estos enunciados de responsabilidad contienen un elemento <resp> con un atributo para especificar si se trata del transcriptor, los revisores o el encargado de producir el documento XML y un elemento <name> para identificar a la persona encargada de la función correspondiente. Se deben completar solamente los nombres que correspondan en la etiqueta <name>, el resto es invariable.
<respStmt>
<resp resp="transcriber">Transcriptor</resp>
<name>Nombre del transcriptor</name>
</respStmt>
<respStmt>
<resp resp="reviewer1">Revisor 1</resp>
<name>Nombre del revisor 1</name>
</respStmt>
<respStmt>
<resp resp="reviewer2">Revisor 2</resp>
<name>Nombre del revisor 2</name>
</respStmt>
<respStmt>
<resp resp="XMLconverter">Conversor a XML</resp>
<name>Nombre del conversor a XML</name>
</respStmt>1.2 <publicationStmt>
Proporciona los datos relativos a la publicación y distribución del documento electrónico.
1.2.1 <publisher>
Contiene la información sobre la organización responsable de la publicación del documento. En nuestra cabecera encontramos dos elementos <orgName> para proporcionar el nombre del grupo GRAFILA (Grupo de Análisis Filológico de Lausana) —acrónimo del grupo de estudio miembro de la red CHARTA— y el de la UNIL. El tipo de institución se detalla con ayuda del atributo type. Para el COSUIZA estos elementos y sus atributos son inmutables:
<publisher>
<orgName type="group">GRAFILA</orgName>
<orgName type="institution">Universidad de Lausana</orgName>
</publisher>1.2.2 <pubPlace>
Contiene el nombre del lugar de publicación del documento electrónico. Para todos los documentos del corpus este elemento tiene el mismo contenido:
<pubPlace>Lausana</pubPlace> 1.2.3 <idno>
Este elemento aparece dos veces en la cabecera y está destinado a identificar el corpus y el número del documento dentro del corpus. Estas informaciones son de utilidad para el macrocorpus CHARTA en el proceso de integración de los documentos de todos sus subcorpus. El contenido de la primera etiqueta es invariable a diferencia del número identificador:
<idno type="corpus">COSUIZA</idno>
<idno type="corpus-num">Número identificador</idno>1.2.4 <distributor>
Recoge la información sobre el o los organismos responsables de la distribución del documento. En nuestra cabecera permanece invariable:
<distributor>Universidad de Lausana</distributor>1.2.5 <availability>
Proporciona la información relativa a la disponibilidad o restricción de publicación de un documento. Dada la naturaleza de los documentos que hacen parte del COSUIZA, en la mayoría de los casos el contenido de esta etiqueta será el mismo. Ahora bien, si se tratara de un documento sobre el cual se aplican ciertos derechos o reservas deberá ser señalado en esta sección. Para todo el resto de los documentos, este elemento se presenta dentro de una etiqueta párrafo (<p>) como se muestra a continuación:
<availability>
<p>Licencia CREATIVE COMMONS</p>
</availability> 1.3 <sourceDesc>
Suministra la información sobre el documento original que sirve de fuente para la edición digital. En virtud de que todos los documentos originales son manuscritos, vamos a utilizar la etiqueta <msDesc> concebida para describir documentos de este tipo.
1.3.1 <msDesc>
1.3.1.1 <msIdentifier> Este elemento contiene todas las etiquetas destinadas a identificar la ubicación exacta de un manuscrito. Vamos a indicar el país, el cantón, la ciudad, el nombre del archivo y el identificador dentro del archivo. El único elemento que no varía es el país, como podemos ver debajo:
<msIdentifier>
<country>Suiza</country>
<region type="canton">Cantón en donde se conserva el documento</region>
<settlement>Ciudad en donde se conserva el documento</settlement>
<repository>Archivo en donde se conserva el documento</repository>
<idno>Identificador dentro del archivo</idno>
</msIdentifier>En caso de que el documento electrónico tenga como fuente el fragmento de un manuscrito se deben indicar los folios (f o ff.) dentro de la etiqueta <idno>.
1.3.1.2 <msContents> Esta etiqueta nos permite describir los contenidos del manuscrito. Incluiremos el resumen que forma parte de todas las cabeceras de las ediciones CHARTA, además señalaremos si se trata de una copia o de un original en el valor del atributo class del elemento <msItem>, el nombre del scriptor, en caso de conocer su nombre y añadiremos su tipo en el atributo type con el valor que corresponda:
<msContents>
<summary>Resumen del contenido</summary>
<msItem class="original/copia">
<editor>
<persName type="escribano/notario">Nombre del scriptor</persName>
</editor>
</msItem>
</msContents>1.3.1.3 <physDesc>
Proporciona la información respecto de las características físicas del documento fuente. Este elemento contiene tres etiquetas mayores:
- <objectDesc> En donde incluiremos los elementos relativos a las medidas del documento y su estado de conservación. En la mayoría de los casos los atributos de los elementos son invariables.
- <handDesc> En donde identificaremos y describiremos la o las manos presentes en el manuscrito. En nuestro ejemplo vamos a suponer que existen dos manos en el manuscrito, una de ellas será la preponderante (major) y, la otra, la secundaria (minor).
- <bindingDesc> En donde podemos describir la encuadernación.
<physDesc>
<objectDesc form="ms">
<supportDesc material="papel">
<extent>
<note>Descripción en prosa del manuscrito</note>
<dimensions scope="all" unit="mm">
<height></height>
<width></width>
</dimensions>
</extent>
<condition><p>Estado de conservación</p></condition>
</supportDesc>
</objectDesc>
<handDesc hands="2">
<handNote resp="#h1" scope="major"><p>Descripción de la mano 1</p></handNote>
<handNote resp="#h2" scope="major"><p>Descripción de la mano 2</p></handNote>
</handDesc>
<bindingDesc>
<binding><p>Descripción en prosa de la encuadernación</p></binding>
</bindingDesc>
</physDesc>1.3.1.4 <history> Etiqueta que contiene la información sobre la historia del manuscrito.
Usaremos la etiqueta <origin> para incluir los elementos específicos a la fecha y locación originales del manuscrito. Todos los atributos son invariables, con la excepción del atributo when.
<history>
<origin>
<origDate when="1688-11-12" type="explicit">1688 noviembre 12</origDate>
<origPlace type="explicit">
<placeName type="settlement">Valladolid</placeName>
<region type="region">Valladolid</region>
<country>España</country>
<geo>41.651981 -4.728561</geo>
</origPlace>
</origin>
</history>El atributo whendebe tener como valor la fecha en formato aaaa-mm-dd.
El contenido del elemento <geo> permite la geovisualización de los documentos en la plataforma Teitok. Para lograr la correcta distribución de los documentos en el mapa, es imprescindible estandardizar las coordenadas geográficas de las diferentes localidades representadas en el mapa. Para acceder al repertorio de coordenadas del COSUIZA pinchar aquí. En los casos en donde solo se sepa el país de origen del documento, el repertorio de coordenadas se encuentra en este enlace. En el supuesto de que una localidad o país no se hallaren en el repertorio se debe contactar al administrador de la página del COSUIZA.
2. <encodingDesc>
Elemento que permite describir los fundamentos editoriales sobre los cuales se ha realizado la edición del documento.
2.1 <projectDesc>
Ofrece las razones por las cuales se ha realizado la codificación del documento. Se trata de una descripción somera dentro de un elemento párrafo (<p>). El contenido será el mismo para todos los documentos del COSUIZA:
<projectDesc>
<p>Edición electrónica preparada para la investigación CHARTA-TEI</p>
</projectDesc>2.2 <editorialDecl>
Contiene los detalles de los principios editoriales aplicados en la codificación del documento. Su contenido se precisa en un elemento párrafo (<p>) y es idéntico en todos los documentos del COSUIZA:
<editorialDecl>
<p>Este documento sigue los criterios de edición CHARTA adaptados para el estándar internacional de marcación electrónica TEI http://www.tei-c.org/index.xml.</p>
</editorialDecl>2.3 <classDecl>
En este elemento se incluye la tipología documental propuesta en los criterios CHARTA.4 Este elemento es invariable y debe estar presente en todos las ediciones electrónicas, puesto que sirve como fuente de la categoría de documento que se señalará posteriormente en la cabecera. Dada la extensión de esta clasificación, se expone solamente un extracto a continuación:
<classDecl>
<taxonomy xml:id="Tip-CH">
<bibl>Tipología CHARTA, propuesta de octubre de 2013</bibl>
<category xml:id="tex-leg">
<category xml:id="tex-leg-ord">
<catDesc>Ordenanzas</catDesc>
</category>
<category xml:id="tex-leg-fue">
<catDesc>Fueros</catDesc>
</category>
<category xml:id="tex-leg-pri">
<catDesc>Privilegios</catDesc>
</category>
<category xml:id="tex-leg-cpue">
<catDesc>Cartas pueblas</catDesc>
</category>
<category xml:id="tex-leg-pra">
<catDesc>Pragmáticas</catDesc>
</category>
</category>
<category xml:id="car-com">
<category xml:id="car-com-con">
<catDesc>Contratos</catDesc>
</category>
<category xml:id="car-com-com">
<catDesc>Compraventas</catDesc>
</category>
<category xml:id="car-com-ces">
<catDesc>Cesiones</catDesc>
</category>
<category xml:id="car-com-don">
<catDesc>Donaciones</catDesc>
</category>
<category xml:id="car-com-conc">
<catDesc>Conciertos</catDesc>
</category>
<category xml:id="car-com-acu">
<catDesc>Acuerdos</catDesc>
</category>
<category xml:id="car-com-per">
<catDesc>Permutas</catDesc>
</category>
<category xml:id="car-com-tru">
<catDesc>Trueques</catDesc>
</category>
<category xml:id="car-com-pac">
<catDesc>Pactos</catDesc>
</category>
<category xml:id="car-com-int">
<catDesc>Intercambios de bienes</catDesc>
</category>
<category xml:id="car-com-ccen">
<catDesc>Cartas de censo</catDesc>
</category>
</category>
</taxonomy>
</classDecl>3. <profileDesc>
Elemento que se utiliza para indicar informaciones no bibliográficas del documento.
3.1 <langUsage>
Esta etiqueta contiene las lenguas utilizadas en el texto. Cada lengua se señala en un elemento <language> que incluye el atributo ident para identificar el código de cada lengua. Este código proviene de la norma ISO-639-1. La mayoría de los documentos del COSUIZA están escritos en castellano y para expresarlo usaremos el código es. En el ejemplo debajo vamos a suponer que estamos frente a un documento en el cual se utilizan dos lenguas, una principal (major) y una secundaria (minor), la extensión de la utilización de cada una en el manuscrito se expresa en el atributo scope, que permite expresar una noción de medida:
<langUsage type="hybrid">
<language ident="es" scope="major">castellano</language>
<language ident="fr" scope="minor">francés</language>
</langUsage>Cuando codifiquemos un documento con más de una lengua debemos precisarlo en el atributo type del elemento <langUsage> con el valor hybrid. No incluiremos este atributo en los documentos monolingües.
3.2 <textClass>
Proporciona la información relativa a la clasificación del documento de acuerdo a una tipología o esquema establecidos. En esta sección recogeremos los identificadores correspondientes de la taxonomía CHARTA presentada previamente. También vamos a incluir las palabras clave propias de la cabecera CHARTA. Supongamos que estamos codificando un testamento, primero buscaremos la categoría Testamento en la taxonomía declarada más arriba y vamos a copiar el valor de su atributo xml:id que es: tes-inv-tes. También vamos a incluir la supracategoría que contiene a Testamento como vemos en la figura debajo:
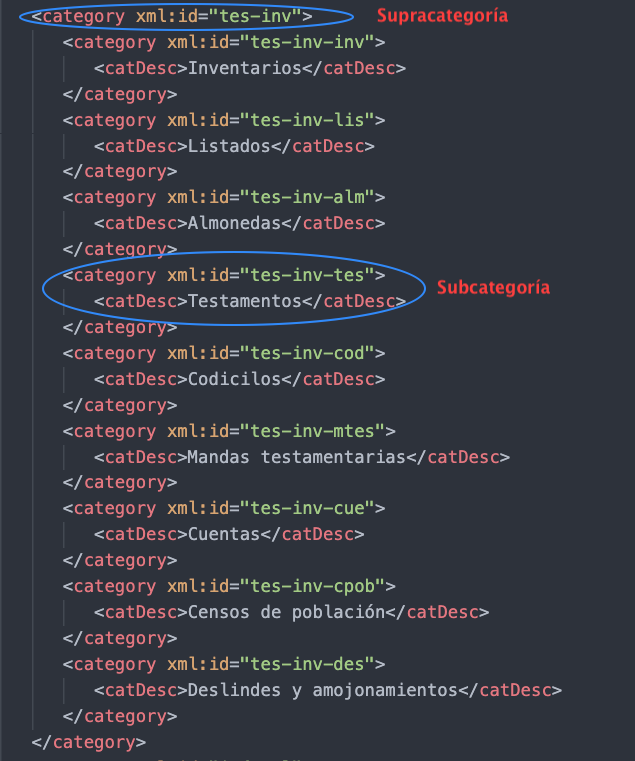
Se indica en primera posición la supracategoría y, luego, la subcategoría, cada una en un elemento <catRef> y en el atributo target se debe escribir el identificador de la categoría antecedido por un signo almohadilla o numeral. La codificación de esta sección de un documento testamentario quedaría como vemos debajo:
<textClass>
<catRef target="#tes-inv"/>
<catRef target="#tes-inv-tes"/>
<keywords>
<term>Palabra clave 1</term>
<term>Palabra clave 2</term>
<term>Palabra clave 3</term>
<term>etc</term>
</keywords>
</textClass>3.3 <particDesc>
Este elemento permite describir los participantes o interlocutores presentes en un texto. Esta sección solo debe utilizarse para ciertas categorías documentales como la correspondencia o, documentos reales en donde existen diversos roles y podemos diferenciar la autoría de la delegación y la escritura. Para cada rol o papel usaremos una etiqueta <person> con un atributo rol cuyo valor va a depender de la categoría documental. En el ejemplo debajo vemos los roles que debemos especificar, en el caso de que sea posible identificar todos los roles, en un documento real.
<particDesc>
<person role="author">
<persName>Autor</persName>
</person>
<person role="ordered">
<persName>Iussor</persName>
</person>
<person role="scriptor">
<persName>Scriptor</persName>
</person>
<person role="signed">
<persName>Firmante</persName>
</person>
</particDesc>En el caso de estar frente a un documento epistolar, se debe utilizar la secuencia a continuación, solamente si es posible identificar estos roles:
<particDesc>
<person role="sent">
<persName>Emisor</persName>
</person>
<person role="received">
<persName>Destinatario</persName>
</person>
</particDesc>3.4 <correspDesc>
Ofrece datos relativos a un documento epistolar. Esta sección debe ser utilizada solamente en la codificación de cartas. Se detalla el lugar de origen y destino además de sus coordenadas respectivas.
<correspDesc>
<correspAction type="sent">
<settlement>
<placeName>Origen</placeName>
<geo>Coordenadas</geo>
</settlement>
</correspAction>
<correspAction type="received">
<settlement>
<placeName>Origen</placeName>
<geo>Coordenadas</geo>
</settlement>
</correspAction>
</correspDesc>4. <revisionDesc>
Este elemento permite registrar las modificaciones que se han hecho en el documento electrónico. Cada intervención se detalla en un elemento <change> con un atributo when para precisar la fecha en que ha tenido lugar la modificación. En el COSUIZA detallaremos dos modificaciones principales: la creación del documento XML y la revisión de la presentación crítica. El atributo whendebe indicar la fecha de la modificación y se puede agregar el atributo whopara indicar las iniciales del colaborador que las ha llevado a cabo.
<revisionDesc>
<change when="aaa-mm-dd" who="MCL">Creación del archivo</change>
<change when="aaa-mm-dd" who= "EDCA">Revisión final de la presentación crítica</change>
</revisionDesc>Documento
<text> es el elemento que contiene los datos textuales en un documento TEI. Hemos señalado que en Teitok la cabecera se ajusta a los criterios de la TEI, sin embargo, en lo que respecta al texto tiene su propio sistema basado en la tokenización de las palabras y de los signos de puntuación. En este sentido, en este tutorial nos limitaremos a presentar solamente los elementos editoriales que CHARTA ha adaptado para su migración a Teitok.
1. Elementos codicológicos
1.1 Numeración de hoja, columna y línea
1.1.1 Inicio de página
| CHARTA | CHARTA-TEITOK |
| {h 1r} | <pb n = “1r” facs = “COSUIZA-0014-1r.jpeg” id = “e-1”/> |
| {h 1v} | <pb n = “1v” facs = “COSUIZA-0014-1v.jpeg” id = “e-23”/> |
La etiqueta <pb> indica el inicio de página.
Es pertinente recordar que, conforme a los criterios CHARTA, todos los textos editados, aunque sean fragmentos de un manuscrito, comienzan por la hoja 1. De modo que el atributo n (número), siempre comienza por el número 1. También consta de un atributo facs para precisar el nombre del archivo facsimilar. Para denominar los archivos de los facsímiles se utiliza el nombre del archivo XML seguido de un guión, la hoja y cara correspondiente: COSUIZA-XXXX-1r. El atributo ìd adjudica un identificador único al elemento <pb>, este identificador es de la forma e-n° y, si bien no es aleatorio, no corresponde necesariamente al número de hoja. Veremos en la sección práctica de este documento que la plataforma de Teitok se encarga de adjudicar este identificador.
1.1.2 Inicio de columna
| CHARTA | CHARTA-TEITOK |
| {a} | <cb n = “a” id = “e-9”/> |
| {h 1ra} | <pb n = “1r” facs = “COSUIZA-0014-1r.jpeg” id = “e-1”/> <cb n = “a” id = “e-9”/> |
El inicio de columna se indica con la etiqueta <cb>. Consta de un atributo n cuyo valor es la letra de la columna y un atributo id. En la segunda línea de la tabla tenemos un inicio de página que coincide con el inicio de una columna, coincidencia muy frecuente en los manuscritos. Como vemos en la marcación CHARTA, página y columna se señalan en una misma secuencia entre llaves. Sin embargo, en la marcación CHARTA-TEITOK el inicio de página y el de columna se indican con etiquetas independientes no anidadas.
1.1.3 Inicio de línea
| CHARTA | CHARTA-TEITOK |
| {1} | <lb n = “1” id = “e-1”/> |
Del mismo modo que los elementos precedentes, el cambio de línea contiene dos atributos: ny id y, el identificador puede no coincidir con el número de línea.
1.1.4 Cambio de línea en acotaciones marginales
| CHARTA | CHARTA-TEITOK |
| | | <lb id = “e-4”/> |
El cambio de línea en el texto marginal se anota con un elemento <lb>, sin embargo, carece de atributo n.
1.2 Deterioro del original
| CHARTA | CHARTA-TEITOK |
| [***] | <gap reason = “ilegible”/> |
| * | <gap reason = “ilegible” extent = “1 char”/> |
| ** | <gap reason = “ilegible” extent = “2 chars”/> |
| *** | <gap reason = “ilegible” extent = “3 chars”/> |
| **** | <gap reason = “ilegible” extent = “4 chars”/> |
| ***** | <gap reason = “ilegible” extent = “5 chars”/> |
| ****** | <gap reason = “ilegible” extent = “6 or more chars”/> |
| [roto] | <gap reason = “roto”/> |
| [doblez] | <gap reason = “doblez”/> |
| [mancha] | <gap reason = “mancha”/> |
Valga recordar que el uso de corchetes en la marcación CHARTA tiene lugar solamente cuando no se sabe el número exacto de caracteres ilegibles. En CHARTA-TEITOK se puede indicar hasta un máximo de cinco letras ilegibles, para cualquier cantidad superior se debe dar el valor 6 or more chars al atributo extent.
Otro cambio que ha tenido lugar en los criterios CHARTA-TEITOK en relación a los criterios CHARTA es que no se puede emplear la marcación relativa a la cantidad de letras ilegibles y la razón del deterioro al mismo tiempo. El transcriptor debe escoger la información que sea pertinente en cada caso.
1.3 Signos o elementos especiales
1.3.1 Firma
| CHARTA | CHARTA-TEITOK |
| [firma: Alfonso de Fonseca] |
<signed> <tok id = “w-1”> Alfonso</tok> <tok id = “w-2”>de</tok> <tok id = “w-3”>Fonseca</tok> </signed> |
| CHARTA | CHARTA-TEITOK |
| [firma mano 2: Alfonso de Fonseca] |
<signed hand = “#h2”>
<tok id = “w-1”> Alfonso</tok> <tok id = “w-2”>de</tok> <tok id = “w-3”>Fonseca</tok> </signed> |
hand, cuyo valor debe estar debidamente mencionado dentro del elemento <handDesc> en los metadatos.
| CHARTA | CHARTA-TEITOK |
|
[firma en ar] [firma en he] |
<signed xml:lang = “ar”/>
<signed xml:lang = “he”/> |
Se usa el atributo xml:lang para marcar una firma en un alfabeto distinto al latino. Nótese que entre corchetes en la marcación CHARTA se aconseja utilizar el código ISO-639-1.
1.3.2 Rúbrica
| CHARTA | CHARTA-TEITOK |
| [rúbrica] |
<figure type = “rúbrica”/> |
| [rúbrica: A] |
<figure type = “rúbrica”> <tok id = “w-1”>A</tok> </figure>. |
La rúbrica se designa con la etiqueta <figure>. Al igual que en la firma, el texto que contiene debe estar tokenizado.
1.3.3 Signos
| CHARTA | CHARTA-TEITOK |
|
[sello] [crismón] [cruz] [signo] [quirógrafo] |
<figure type = “cruz”/> |
Se emplea la etiqueta <figure> para los signos especiales. En el ejemplo hemos usado solamente el signo de la cruz; no obstante, se debe dar el valor que corresponda en cada caso al atributo type.
1.3.4 Impreso
| CHARTA | CHARTA-TEITOK |
| [impreso: texto] |
<hi rend = “impreso”> <tok id = “w-1”>texto</tok> </hi> |
Los pasajes impresos se marcan con la etiqueta <hi> (highlighted). Este elemento se utiliza para destacar fragmentos que se diferencian de su contexto. El atributo rend(rendition) sirve para indicar cómo se representa un elemento en el manuscrito. En este contexto, el valor de este atributo es invariable. Como se ha señalado previamente, el texto debe estar tokenizado.
1.4 Intervenciones en el texto
1.4.1 Tachado, raspado, cancelado
| CHARTA | CHARTA-TEITOK |
| [tachado] | <del type = “tachado”/> |
| [tachado: texto] |
<del type = “tachado”> <tok id = “w-1”>texto</tok> </del> |
| [tachado mano 2: texto] |
<del type = “tachado” hand = “#h2”> <tok id = “w-1”>texto</tok> </del> |
Usamos la etiqueta <del> (deletion) para marcar un fragmento suprimido. Utilizaremos la misma secuencia para otras intervenciones como raspado y cancelado. Para ello, se debe completar el valor del atributo type con la intervención que corresponda.
1.4.2 Sobrescrito
| CHARTA | CHARTA-TEITOK |
| mu[sobrescrito: l+g]er |
<tok id = “w-1”>mu <subst><del type = “sobrescrito”>l</del><add type = “sobrescrito”>g</add></subst> er</tok> |
Puesto que esta es una intervención que tiene lugar dentro de una palabra o un <tok>, integramos los elementos propios a la intervención en el interior de esta etiqueta. Utilizamos <subst> para indicar la supresión y adición de elementos en el texto. Para indicar la supresión empleamos la etiqueta <del> cuyo contenido es, en este caso, la letra l y, para el texto sobrescrito, la letra g, usamos <add>. Ambas deben contar con un atributo typepara declarar el tipo de intervención.
1.4.3 Sobrerraspado
| CHARTA | CHARTA-TEITOK |
| [sobrerraspado: muger] |
<subst> <del type = “sobrerraspado”/> <add type = “sobrerraspado”>muger</add> </subst> |
Utilizamos los mismos elementos que en el caso precedente, sin embargo, dado que es muy improbable que podamos restituir el texto raspado, la etiqueta <del> no lleva contenido. El texto, en este caso muger, debe ir correctamente tokenizado, cosa que no hacemos en este ejemplo para no sobrecargarlo visualmente. Si el sobrerraspado se hallase en el interior de una palabra, la intervención debe indicarse en el interior de la etiqueta <tok> como podemos apreciar en el ejemplo del sobrescrito.
1.4.4 Interlineado
| CHARTA | CHARTA-TEITOK |
| [interlineado: texto] | <add place = “interlineado”>texto</add> |
Para el interlineado utilizamos la etiqueta <add> que consta de un atributo placecuyo valor es invariable. Si el interlineado fuese obra de otra mano, esto se indica agregando el atributo hand con el valor “#h2” o el que corresponda a la mano debidamente declarada en los metadatos. Este mismo principio se puede aplicar para todo el resto de las intervenciones hechas por otra mano en el texto.
1.4.5 Margen
| CHARTA | CHARTA-TEITOK |
| [margen: texto] | <add place = “margen”>texto</add> |
| [margen mano 2: texto] | <add hand = “#h2” place = “margen”>texto</add> |
Usamos las mismas etiquetas que en el caso del interlineado, sin embargo, el valor del atributo placecambia. Opcionalmente, se puede añadir el lado en el cual tiene lugar la intervención al margen. En cuyo caso el atributo placellevaría por valor: margen izquierdo, margen derecho, margen superior o margen inferior. Como en el resto de los casos previamente señalados y, como se puede ver en la tabla, también se puede precisar un cambio de mano.
📝 Para agregar el texto de un sobre se puede utilizar el mismo marcado que se usa para el margen. Se debe escribir sobre en el valor del atributo
place
1.4.6 Encabezamiento y título
| CHARTA | CHARTA-TEITOK |
| [encabezamiento: texto] | <div type = “encabezamiento”>texto</div> |
| [título: texto] | <div type = “título”>texto</div> |
Se emplea la etiqueta <div> (text division) para el encabezamiento y el título. Este elemento se utiliza para englobar párrafos que forman parte de una unidad. Se añade el atributo typepara detallar el tipo de subdivisión.
1.4.7 Blanco
| CHARTA | CHARTA-TEITOK |
| [blanco] | <gap reason = “blanco”>texto</gap> |
Este elemento se marca con las mismas etiquetas que en los casos de deterioro del original, en cambio, el valor del atributo reason es blanco.
1.5 Intervenciones en el texto por parte del editor
Las conjeturas del editor se pueden clasificar de acuerdo al grado de certeza con el que se realizan.
1.5.1 Conjetura cierta
| CHARTA | CHARTA-TEITOK |
| [ilegible: texto] | <supplied reason = “ilegible”>texto</supplied> |
| [roto: texto] | <supplied reason = “roto”>texto</supplied> |
| [doblez: texto] | <supplied reason = “doblez”>texto</supplied> |
| [mancha: texto] | <supplied reason = “mancha”>texto</supplied> |
Se utiliza el elemento <supplied> para agregar una conjetura con certeza. La razón se añade en el valor del atributo reason.
1.5.2 Conjetura incierta
| CHARTA | CHARTA-TEITOK |
| [ilegible: texto] | <unclear reason = “ilegible”>texto</unclear> |
| [roto: texto] | <unclear reason = “roto”>texto</unclear> |
| [doblez: texto] | <unclear reason = “doblez”>texto</unclear> |
| [mancha: texto] | <unclear reason = “mancha”>texto</unclear> |
La conjetura con menos certeza se trata de manera similar a la precedente, sin embargo, se utiliza la etiqueta <unclear>. Se debe recordar que todo texto en el interior de estas etiquetas debe estar tokenizado.
2. Transcripción paleográfica y presentación crítica
2.1 Transcripción paleográfica
| CHARTA | CHARTA-TEITOK |
| villa | <tok id = “w-1”>villa</tok> |
Para marcar las palabras empleamos la etiqueta <tok>, la cual siempre debe constar de un atributo idpara su identificador de la forma "w-n°". El contenido de esta etiqueta es la transcripción paleográfica de la palabra, en nuestro ejemplo: villa. Sabemos que esta palabra no sufrirá ningún cambio en la presentación crítica, a menos que esté precedida de un punto y tengamos que poner la v en mayúscula. En este ejemplo supondremos que villa no requiere de ninguna modificación en la presentación crítica. En todos los casos similares la etiqueta <tok> no lleva otro atributo que el de id.
2.2 Presentación crítica
| CHARTA | CHARTA-TEITOK |
| uilla | <tok id = “w-1” nform = “villa”>uilla</tok> |
En este caso debemos cambiar la grafía u por la v, ya que la primera se presenta con valor consonántico. Para ello, agregamos el atributo nform para escribir la forma que deseamos para nuestra presentación crítica.
2.3 Abreviaturas
| CHARTA | CHARTA-TEITOK |
|
escriu |
<tok id = “w-1” form = “escrui” fform = “escruiano” nform = “escrivano”>escriu<ex>ano</ex> |
Para indicar la presencia de una abreviatura, debemos hacerlo por medio del elemento <ex>. Dado que es un fenómeno que ocurre en el interior de una palabra, su etiqueta debe situarse al interior de la etiqueta <tok>. Ante la presencia de una abreviatura se deben agregar dos atributos a esta etiqueta. En primer lugar se añade el atributo form, cuyo valor debe ser la forma escrita, sin desarrollar la abreviatura ni incluir el elemento <ex>. Este atributo se usa en todos los casos en donde encontramos otra etiqueta en el interior de una etiqueta <tok>. En segundo lugar, se incorpora el atributo fform cuyo valor debe ser la palabra con su abreviatura expandida. Finalmente, como el ejemplo requiere la modificación de la grafía u por v, al igual que en el ejemplo precedente, añadimos un atributo nform.
📝 Recordemos que cuando se agregan atributos a las etiquetas, estos deben tener un valor, de otro modo no los añadiremos. En el caso antes dicho, la abreviatura exige la existencia de los atributos
formyfform, pero no denform.
2.4 Unión y separación de palabras
| CHARTA | CHARTA-TEITOK |
| dela |
<tok id = “w-1” nform = “de la”>dela <dtok id = “d-1-1” form = “de”/> <dtok id = “d-1-2” form = “la”/> </tok> |
Se trata la unión de palabras con la adición del elemento <dtok> el cual no lleva contenido, sin embargo, debe imperativamente llevar un atributo form. También debe constar de un identificador que incluye el número identificador del <tok> que lo contiene. En los casos que se requiera, la etiqueta <dtok> debe llevar los atributos fformy nform. No obstante, esto no descarta la necesidad de también incluir el atributo nform en el <tok> principal.
| CHARTA | CHARTA-TEITOK |
|
juris prudencia |
<tok id = “w-1” nform = “jurisprudencia”>juris prudencia</tok> |
La separación irregular de palabras se conserva en el contenido de la etiqueta <tok> y se normaliza en el atributo nform.
2.5 Ruptura de palabra a final de renglón
| CHARTA | CHARTA-TEITOK |
|
razo{2}nes |
<tok id = “w-1” form = “razones”>razo<lb n = “2” id = “e-9”/>nes</tok> |
Se introduce la etiqueta de salto de línea <lb> en el interior del token en el que ocurre la ruptura. Recordemos que todo token que lleve otra etiqueta en el interior debe añadir el atributo formcon la palabra en su forma de transcripción paleográfica.
2.6 Cambio de lengua
| CHARTA | CHARTA-TEITOK |
| [en.: fish] |
<foreign xml:lang = “en”> <tok id = “w-1”>fish</tok> </foreign> |
Se trata el cambio de lengua con la etiqueta <foreign>, que permite indicar la presencia de una lengua distinta a su contexto. Se debe añadir el código ISO-639-1 como valor del atributo xml:lang.
2.7 Signos de puntuación
| CHARTA-TEITOK |
| <tok id = “w-1” nform = “.”>,</tok> |
Se ha señalado previamente que en Teitok los signos de puntuación son considerados tokens, de modo que para editar un signo de puntuación se añade un atributo nformcon el signo deseado en la presentación crítica.
| CHARTA-TEITOK |
| <tok id = “w-1” nform = “–”>,</tok> |
Para eliminar un signo de puntuación de la presentación crítica, se escriben dos guiones en el atributo nform.
| CHARTA-TEITOK |
| <tok id = “w-1” nform = “,”><ee/></tok> |
Si se desea añadir un signo de puntuación en la presentación crítica, es necesario agregar una etiqueta <ee/> en el interior del elemento <tok> y se escribe en el atributo nform el signo deseado.
2.8 Etiquetado gramatical
| CHARTA-TEITOK |
| <tok id = “w-1” pos = “VMIS3S0” lemma = “venir”>vino</tok> |
Para indicar la anotación morfosintáctica se añaden dos atributos: pos(part of speech) para incluir la categoría gramatical y lemma para la forma lematizada.
📝 Para obtener más detalles sobre las categorías gramaticales y los códigos a emplear en el atributo
posse recomienda visitar la página del etiquetario.
Automatización en la plataforma
En esta sección se presentan las instrucciones para la edición de textos en la página del COSUIZA. Ahora bien, aunque la sección precedente pueda parecer abrumadora por la profusión de información, es absolutamente necesario que el lector esté al tanto de la estructura y contenido de los documentos codificados.
En este apartado veremos que todo el proceso de codificación está ampliamente automatizado en la plataforma, sin embargo, las
aplicaciones informáticas, aunque son convenientes, no siempre son infalibles.
El documento que codificaremos es una carta que se conserva en la Biblioteca cantonal y universitaria de Friburgo:

Biblioteca cantonal y universitaria de Friburgo, B-126
Acceso
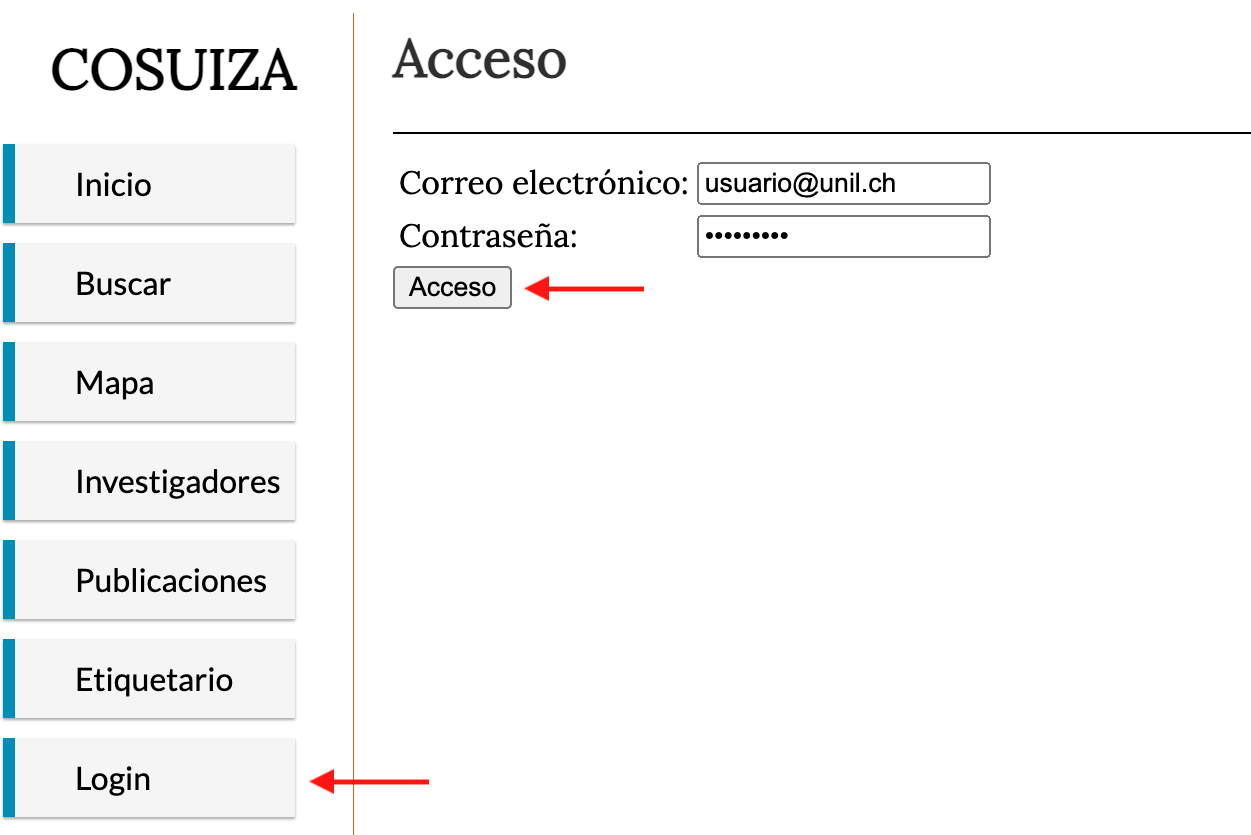
Como se ha mencionado en el primer apartado, para hacer ediciones en el COSUIZA, es necesario tener una cuenta de usuario o administrador. Satisfecho este requisito, ir a la página de inicio del COSUIZA. En el menú principal seleccionar la pestaña login e ingresar usuario y contraseña.
Creación de archivo XML
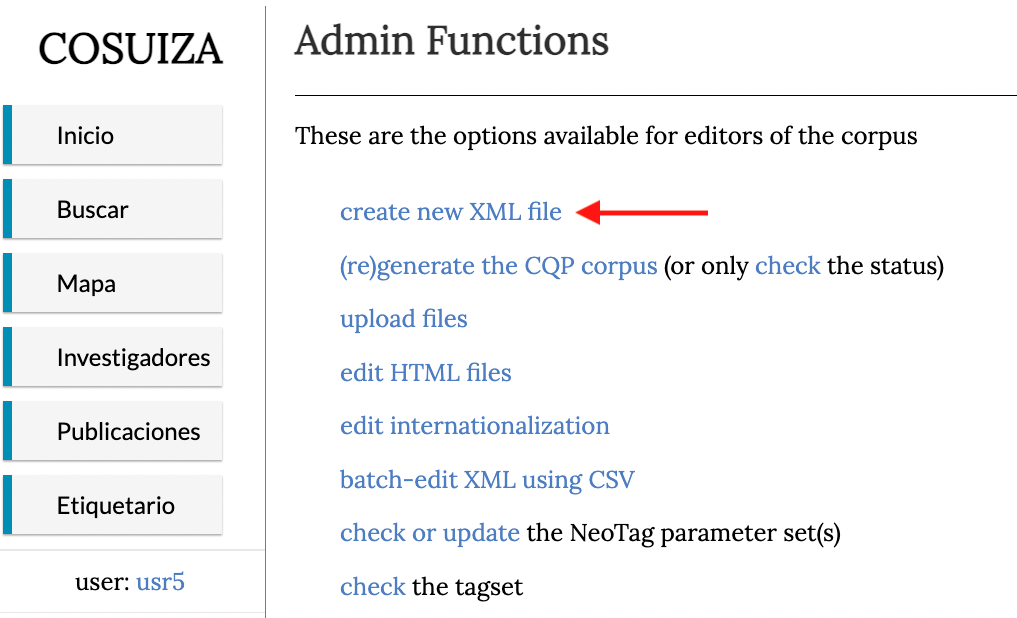
Tras identificarse en la plataforma, se abrirá una página con la lista de funciones con privilegios de administrador. Se debe pinchar en la primera opción create new XML file, como vemos a continuación:
Esta selección nos dirige a una página en donde se debe denominar el archivo, escoger las opciones relativas a los metadatos y agregar su contenido textual.
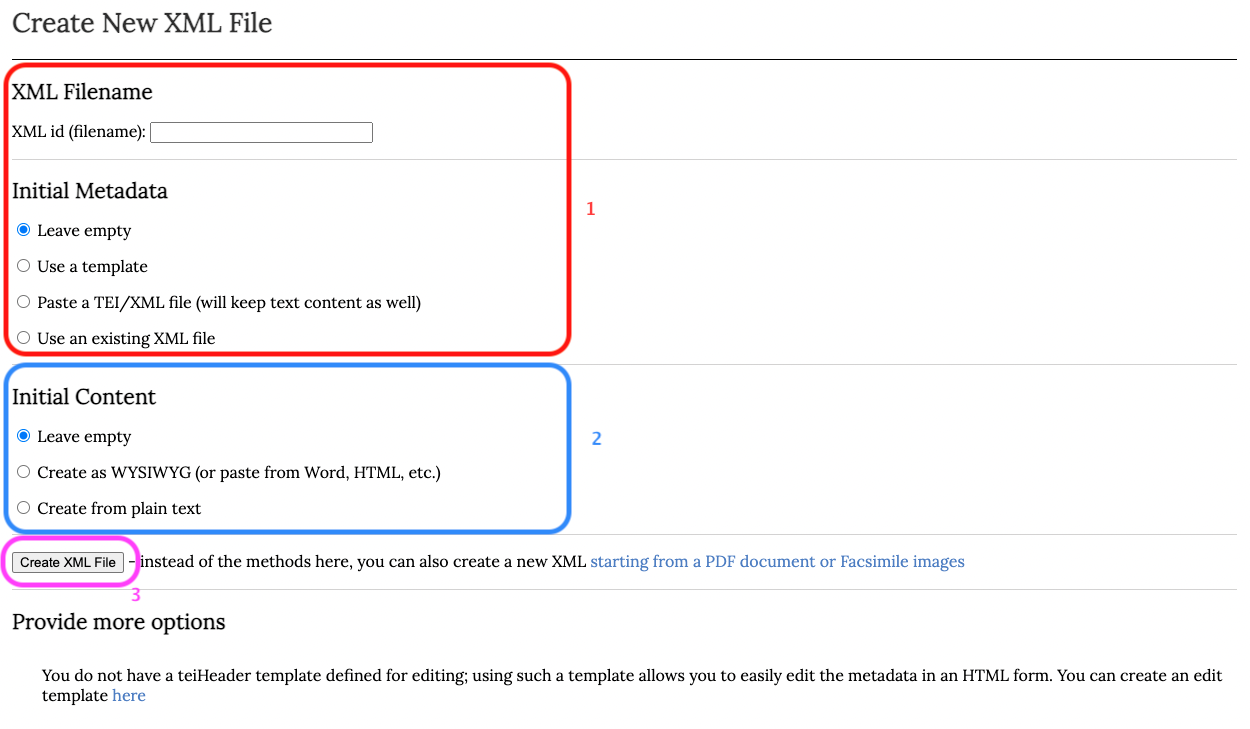
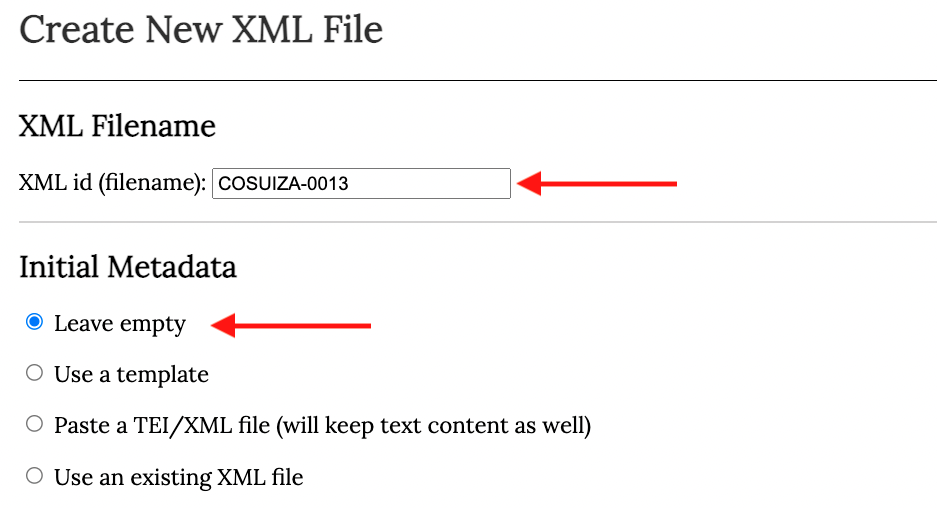
1. En primer lugar se completa el campo XML id (filename) con el nombre del archivo siguiendo el estándar expuesto en § 1.1.1. Para los metadatos, se debe escoger la opción Leave empty (posteriormente nos ocuparemos de los metadatos).
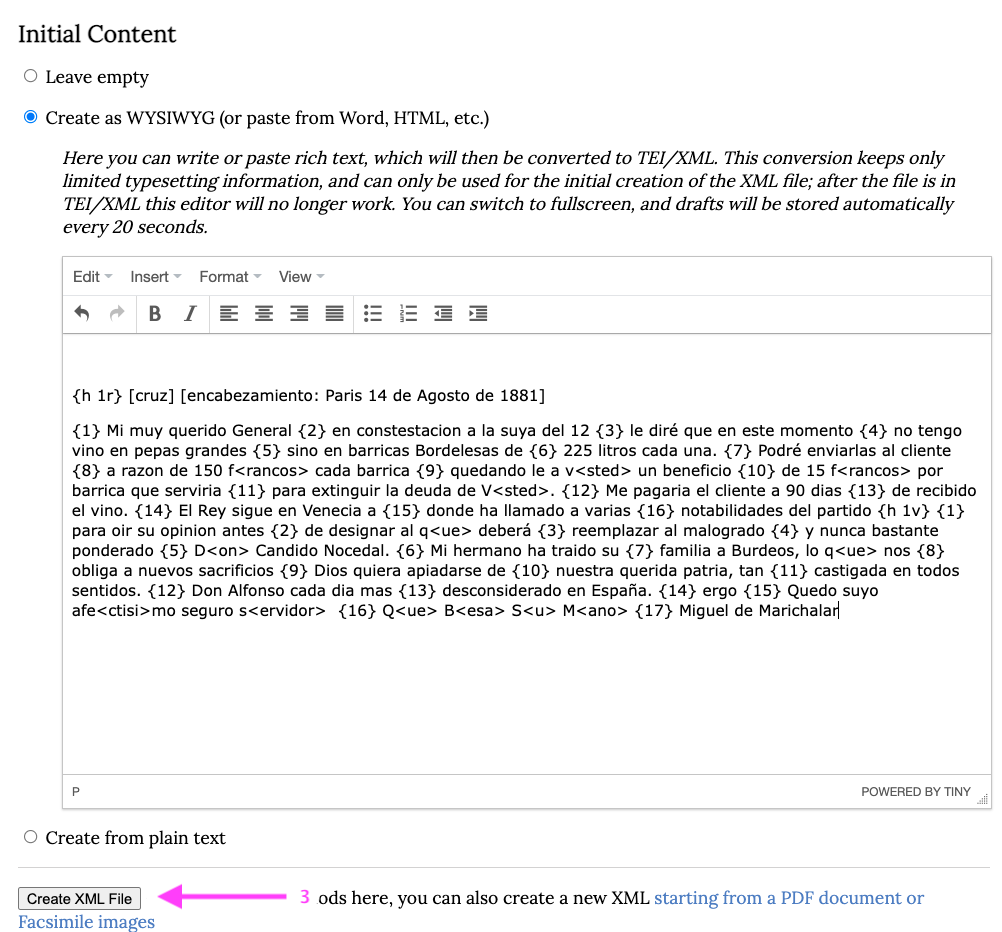
2. Para el contenido textual, pinchamos la opción Create as WYSIWYG que nos permite transcribir directamente en el cuadro de texto o pegar el texto del portapapeles. Vamos a pegar la transcripción paleográfica de nuestro documento hecha conforme a los criterios CHARTA.
3. Verificar que no existan errores, que cada corchete de apertura vaya acompañado de un corchete de cierre y que las anotaciones hechas entre corchetes no se encuentren escritas en cursiva. Posteriormente, pinchamos en el botón Create XML File en la parte inferior izquierda de la pantalla.
Esta acción crea un archivo XML mínimo con el elemento raíz <TEI>, sus dos elementos hijos, <teiHeader> y <text> y, dos elementos <p> que contienen los dos párrafos de nuestra carta. Sin embargo, este archivo XML no contiene ningúna etiqueta previamente presentada en la guía de etiquetado. Para aplicar esta marcación vamos a pinchar en la opción TP (CHARTA 3.0) en el apartado Admin options, como vemos en la imagen debajo:
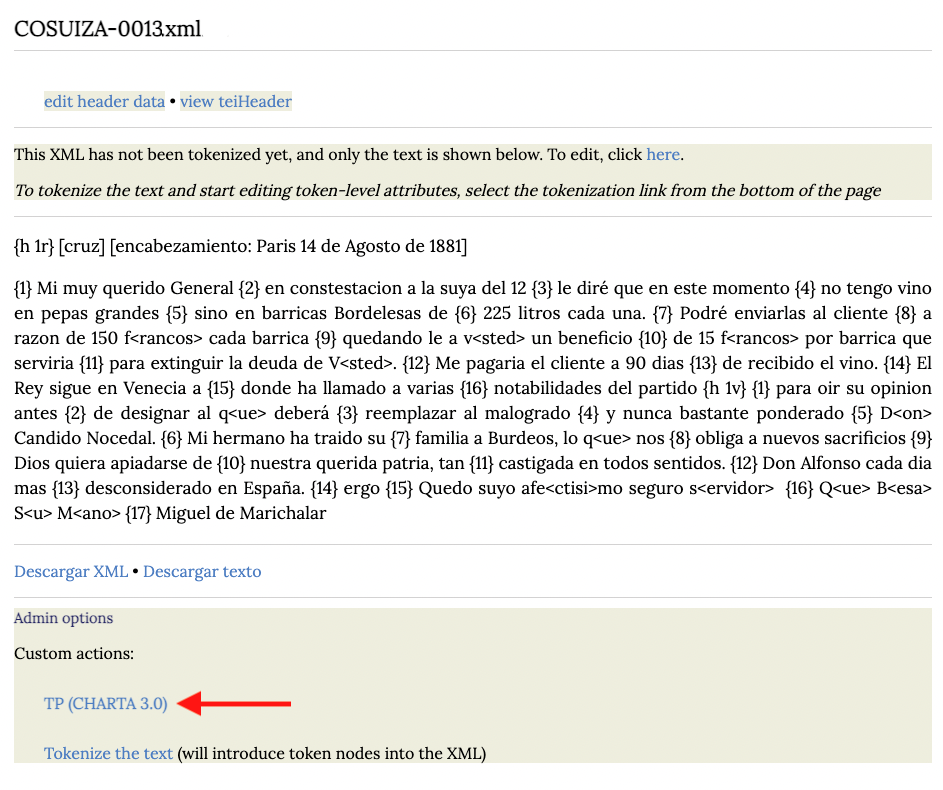
Esta etapa permite marcar elementos textuales como los cambios de línea, de página, los signos y las firmas, entre otros. En la imagen debajo vemos un mensaje subrayado, este mensaje nos indica que la secuencia de comandos se aplicó correctamente. De no hacerlo, es necesario reiniciar el proceso desde la creación del archivo XML. Si el script TP (CHARTA 3.O) se ha aplicado correctamente, pinchar en el enlace indicado en la parte inferior de la imagen a continuación:

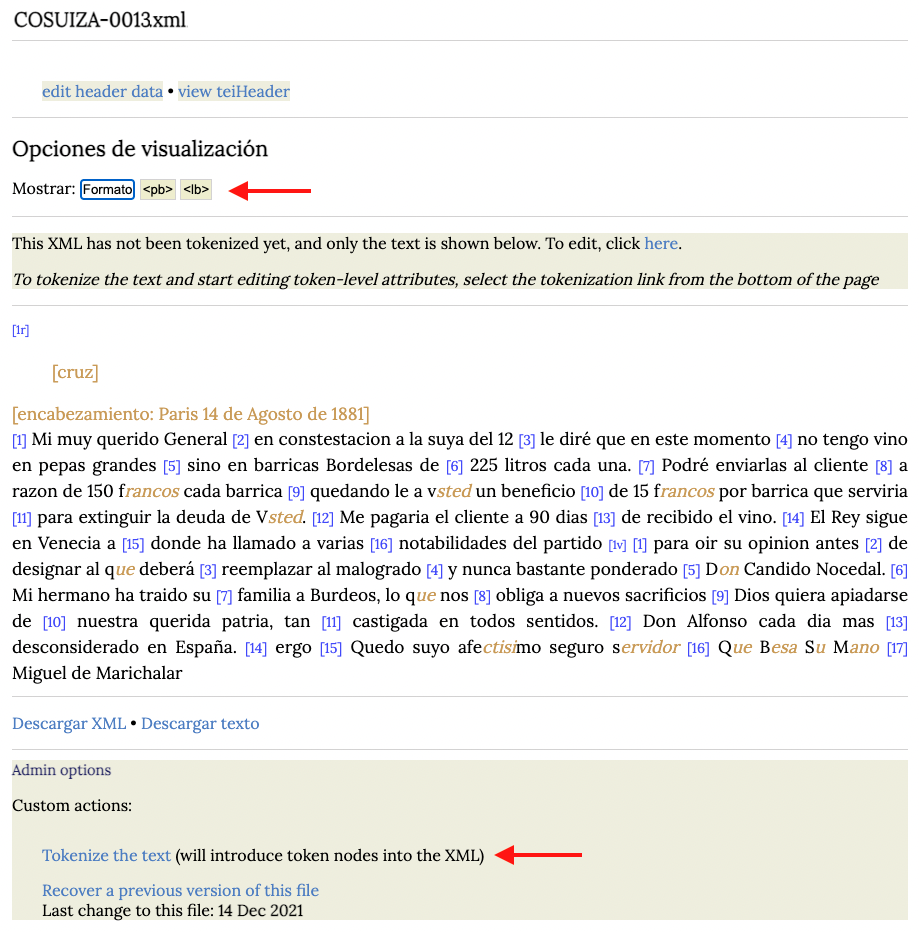
Tokenización del texto
La aplicación del script TP (CHARTA 3.O) nos permite visualizar los elementos que ya han sido marcados. Si hacemos clic en el botón <pb> podemos ver los cambios de página y, el botón <lb> nos permite visualizar las líneas. Para poder modificar cada palabra y poder aplicar el etiquetado morfosintáctico, debemos aplicar otro programa especial para dar a cada palabra una etiqueta <tok>. Para ello, pincharemos en el enlace Tokenize the text en la parte inferior de la página. Esta acción nos permite hacer clic en cualquiera de las palabras del texto para poder editarla.
Edición de token
En la imagen debajo hemos hecho clic en la palabra Bordelesas para poder cambiar la B inicial por b. Esto abre una página en donde podemos agregar cualquiera de las formas posibles de un token. En la imagen debajo hemos completado el campo nform Critical form con la forma de la presentación crítica. Pinchar en Save en la parte inferior izquierda de la página para volver a la visualización del documento.
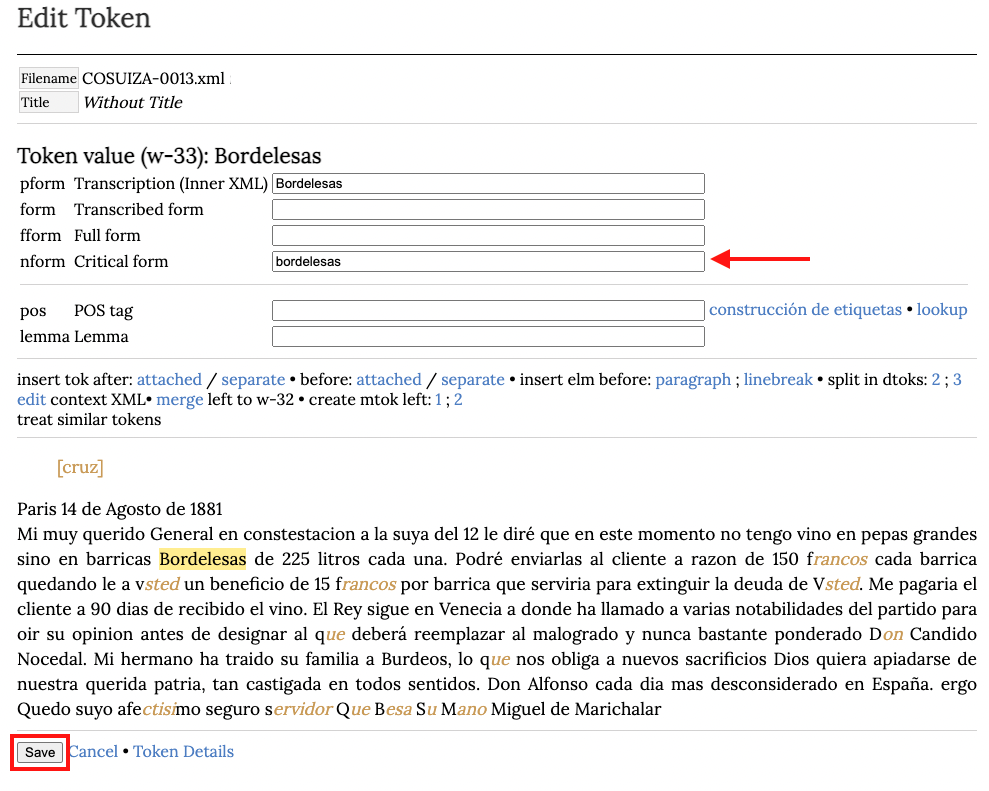
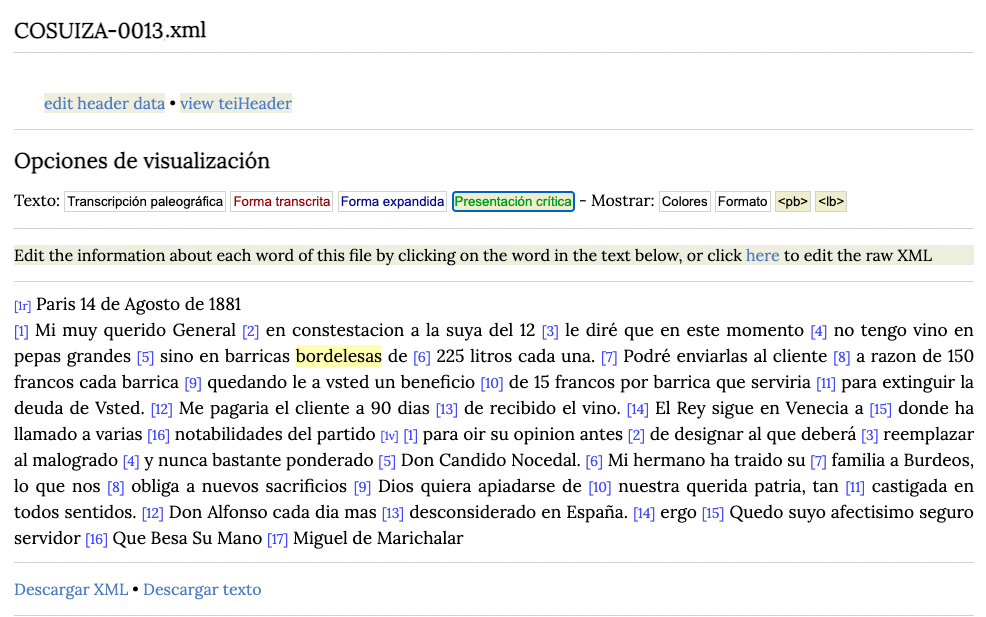
Como podemos ver en la imagen a continuación, solo hay que añadir una nform a una palabra para que se haga visible el botón que permite visualizar la presentación crítica. Debajo vemos bordelesas con b inicial como corresponde.
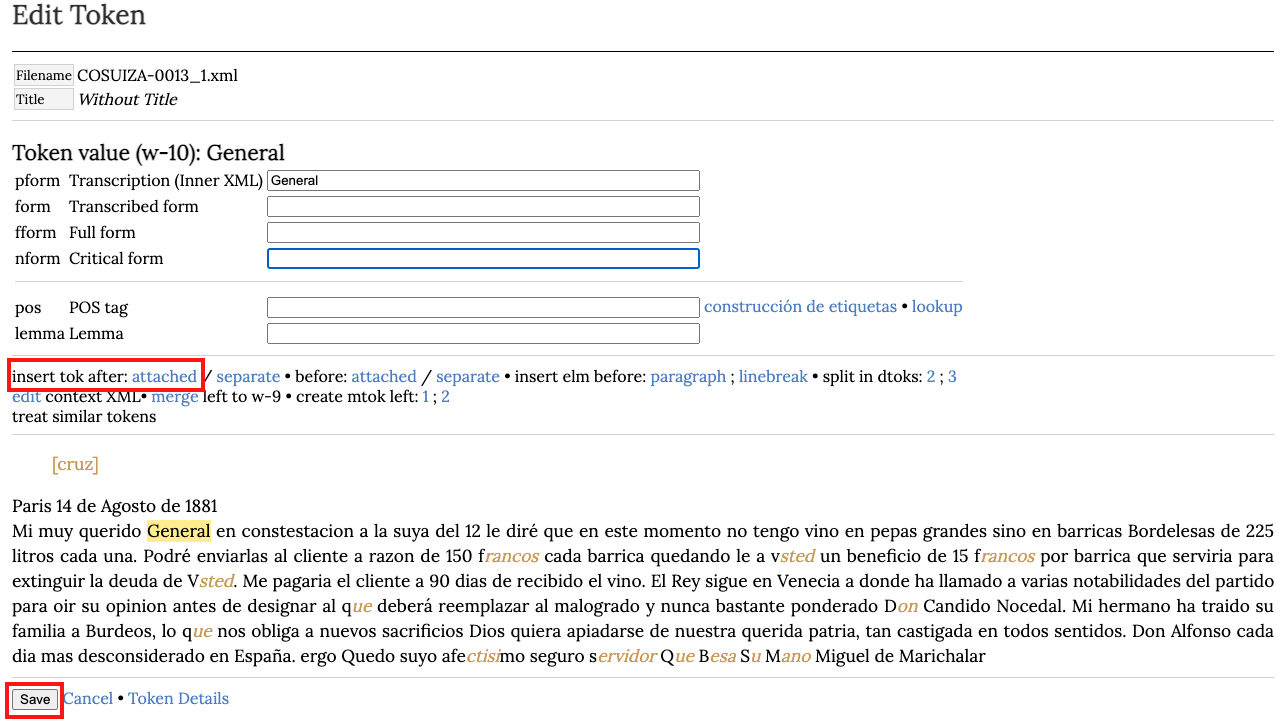
Puntuación
Vamos a añadir dos puntos después del saludo en nuestra carta. Para ello, pinchamos en la palabra General, en seguida hacemos clic en insert tok after: attached. Esto añadirá un tok sin dejar un espacio en blanco antes. La plataforma reconoce esta instrucción, por lo tanto, solamente se debe agregar los dos puntos en el campo nform Critical form y hacer en clic en Save.
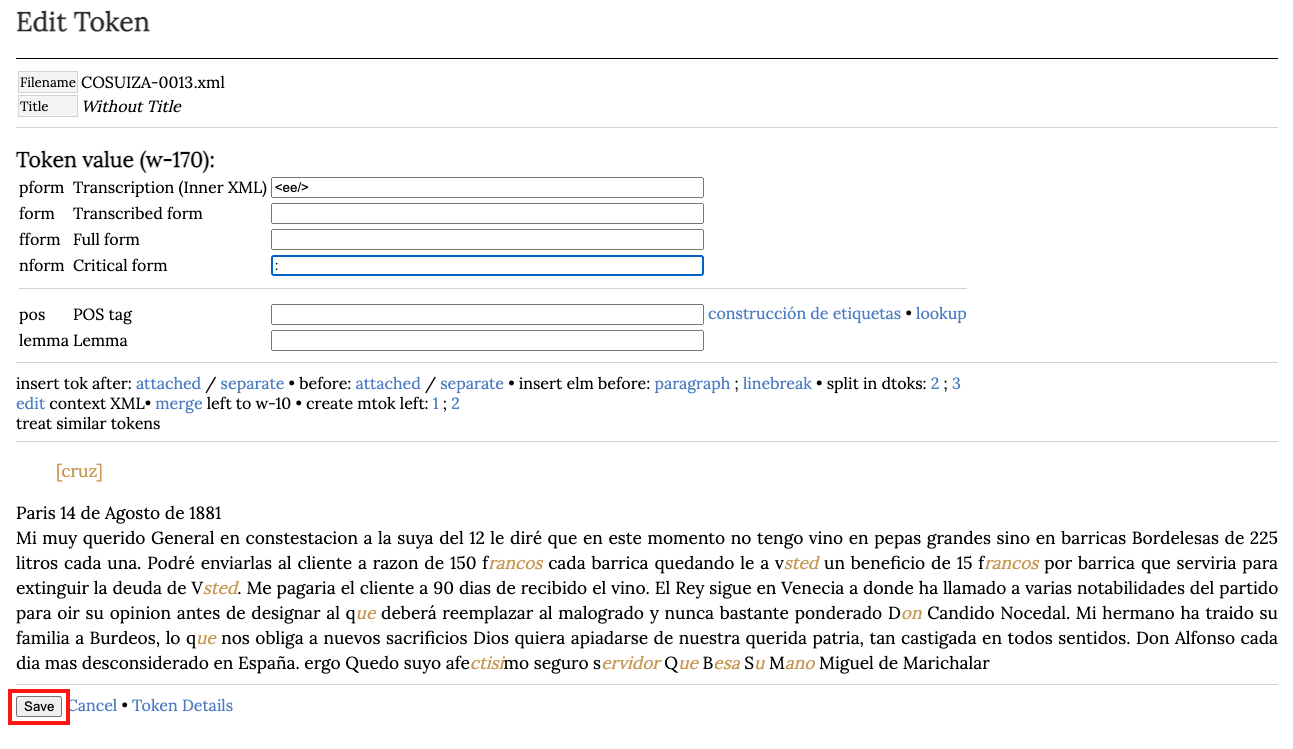
Recordemos que para cambiar un signo de puntuación, simplemente se añade el signo deseado en la presentación crítica en el campo nform Critical form. Para eliminar un signo de puntuación de la presentación crítica, se agregan dos guiones en el campo nform Critical form del token que se desea eliminar.
Unión y separación irregular de palabras
La unión de palabras se trata agregando etiquetas <dtok> en el interior de la etiqueta <tok>. Esta opción se presenta en la ventana de edición de token como vemos en la imagen debajo. Pincharemos en split in dtoks: 2.
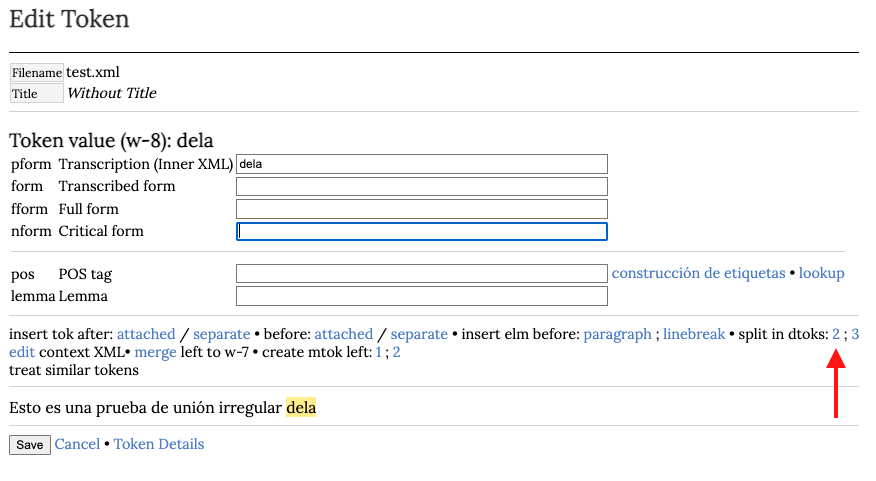
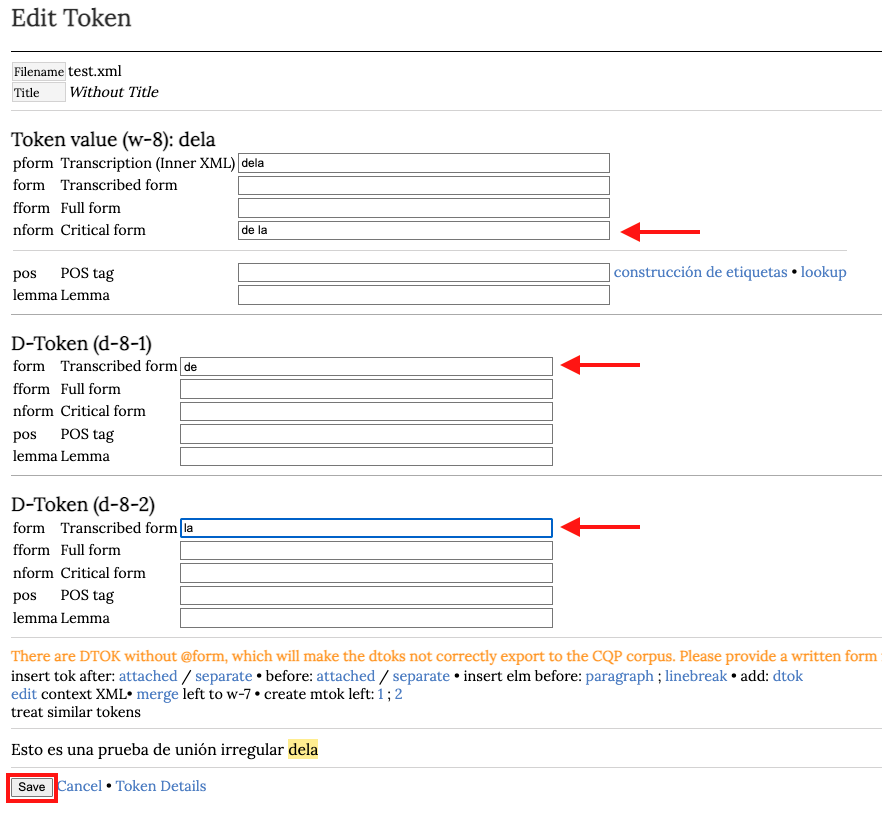
Esto crea los dtok con sus campos para las diferentes formas posibles. La forma de la presentación crítica se conserva en el token principal, por lo tanto, separamos las palabras en este campo. Los dos dtok deben tener siempre el campo form completo. Por último, hacemos clic en Save.
La separación irregular de palabras se trata con la opción merge en la página de edición de token. Primero, se pincha en el segundo o último token de la secuencia que se desea unir.
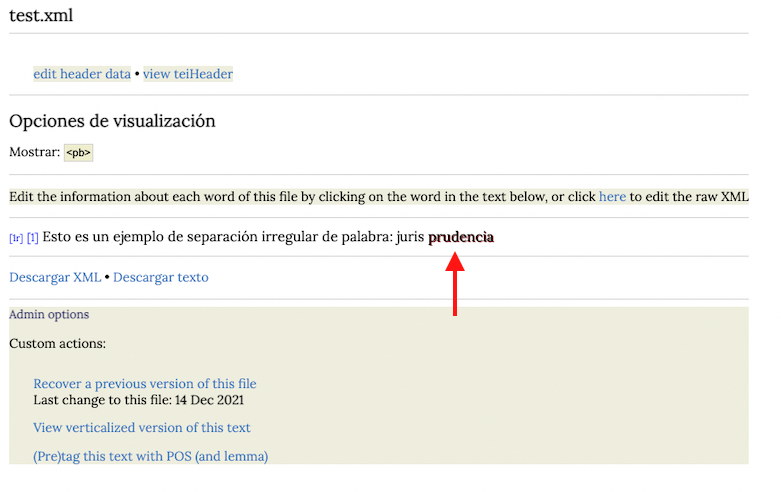
Luego hacemos clic en merge:
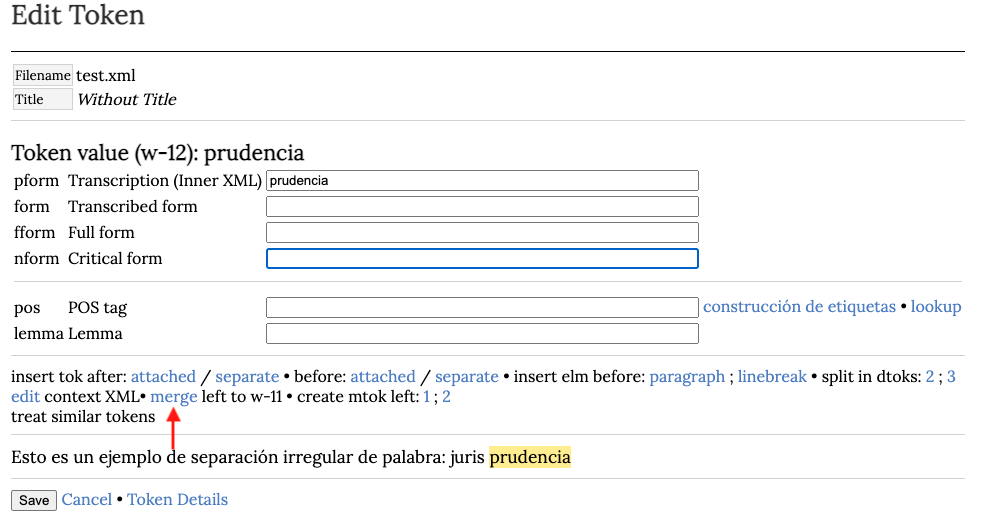
Esta acción abre una página en donde se presenta la visualización del token que resulta de la fusión. Pinchamos en Save.
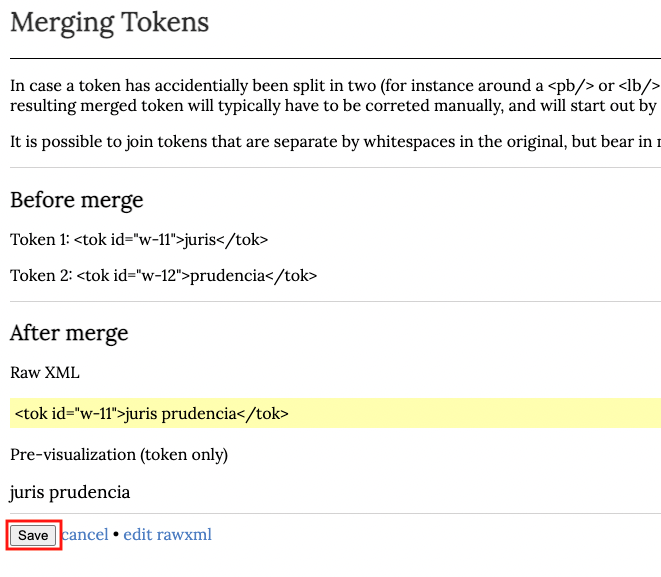
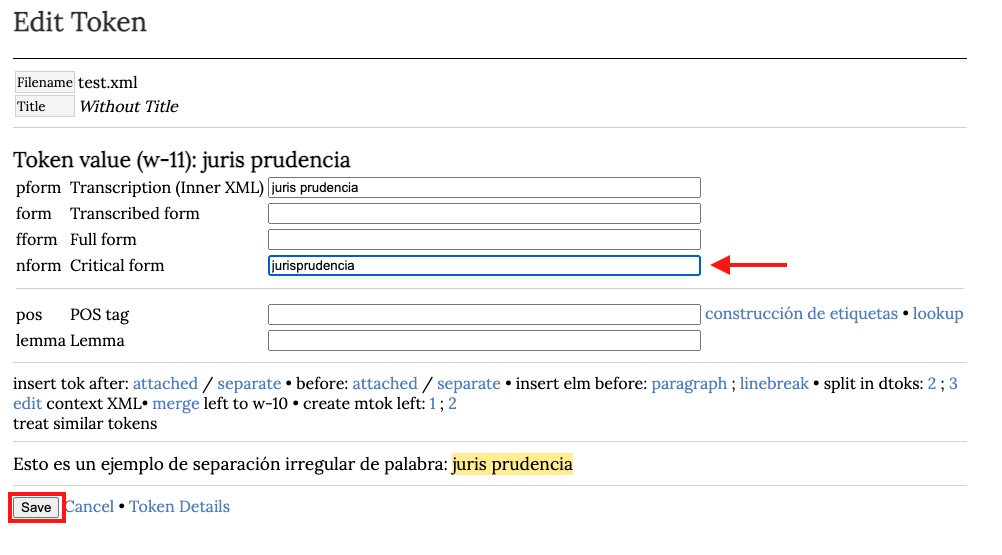
Finalmente, completamos la nform Critical form con la palabra en la forma de la presentación crítica y pinchamos en el botón Save.
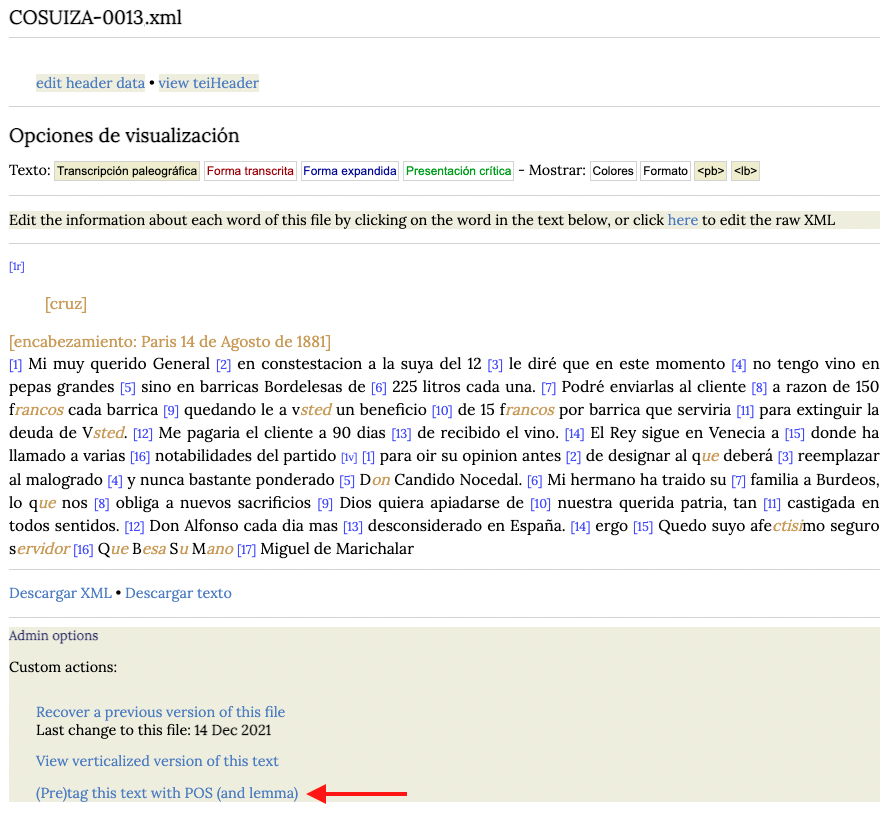
Etiquetado morfosintáctico y lematización
Para aplicar el etiquetado morfosintáctico es indispensable haber realizado las tareas de edición precedentes en todo el documento. Solo entonces podemos aplicar el etiquetado automático. Para ello, debemos pinchar en el enlace (Pre)tag this text with POS (and lemma).
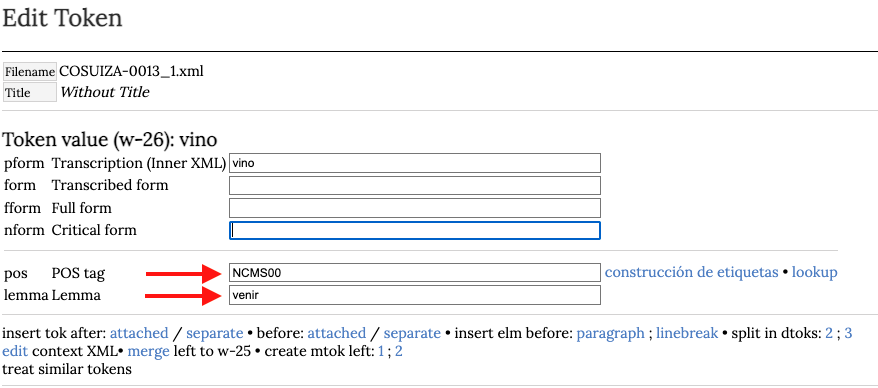
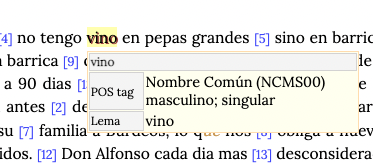
El resultado que se obtenga con la aplicación de este etiquetado automático debe ser cuidadosamente revisado por el editor. Para evitar equivocaciones como la que vemos en la imagen debajo. Al apoyar el cursor sobre la palabra vino vemos que la categoría adjudicada automáticamente no es correcta. Hemos obtenido VMIS3S0:

Ahora bien, evidentemente si examinamos el contexto, esta categoría no corresponde, al no tratarse de un verbo, sino de un sustantivo. Debemos modificar este campo directamente en la página de edición del token como vemos en la siguiente imagen:
Para mas información sobre el etiquetario pinchar aquí.
Volvemos a la visualización de nuestro documento y la viñeta presenta la información corregida.
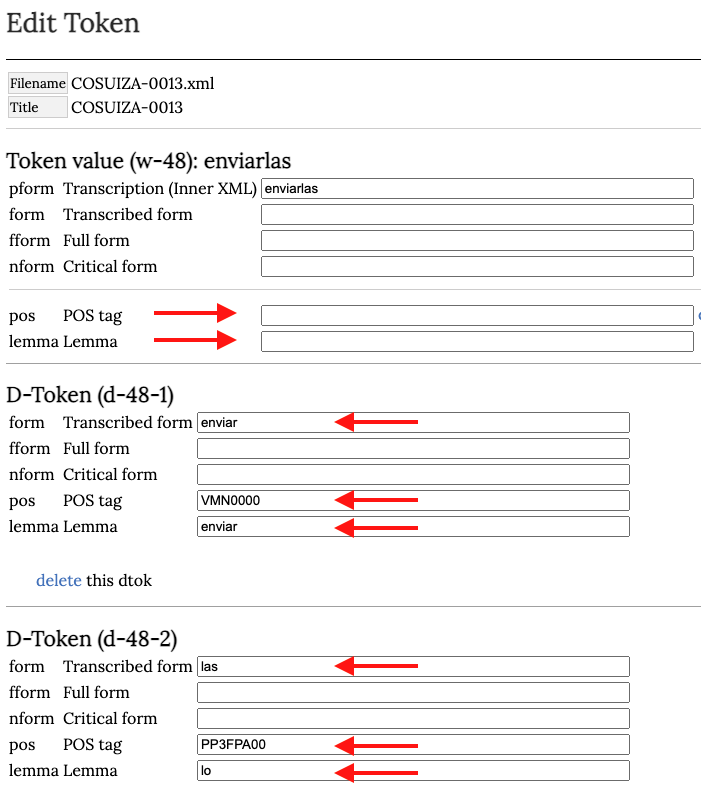
Esta acción debe repetirse con otros fenómenos que el editor podrá encontrar al revisar el resultado del etiquetado automático. En cuanto a los pronombres átonos, el editor deberá separar los enclíticos de los verbos utilizando la opción split in dtoks: 2.

En la página de edición del token vamos a borrar el campo pos POS tag y lemma Lemma del token principal y completaremos los campos que correspondan en cada dtok.5
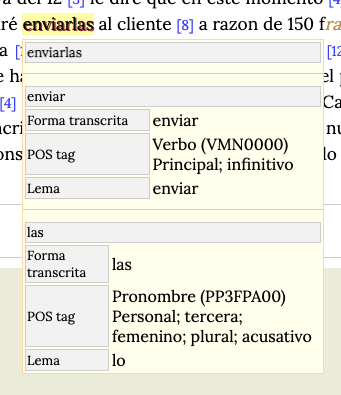
En la página de visualización del documento podemos ver la información correcta aparecer en la viñeta del token.
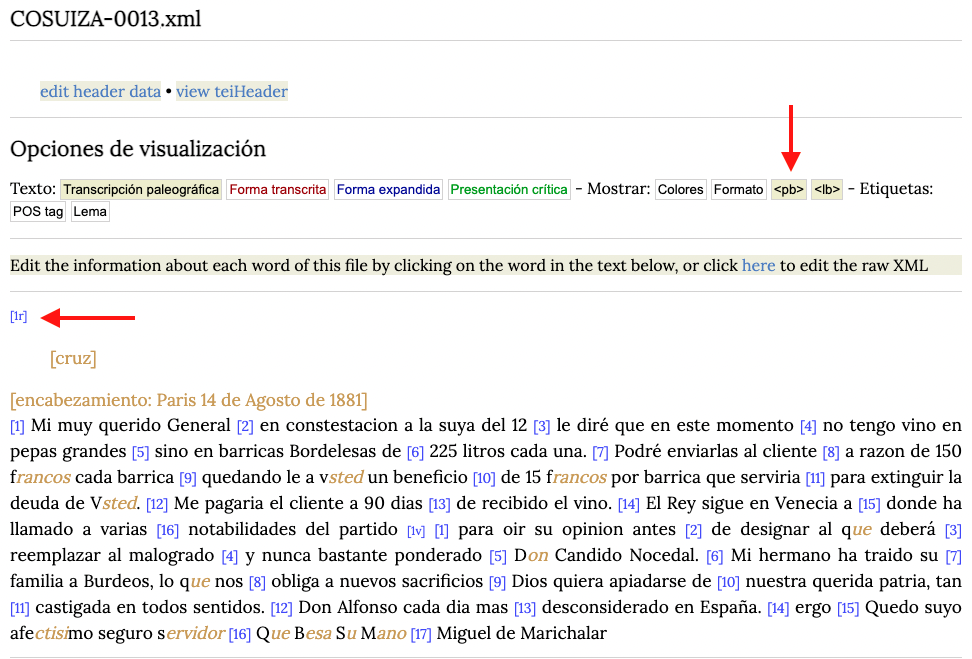
Facsímil
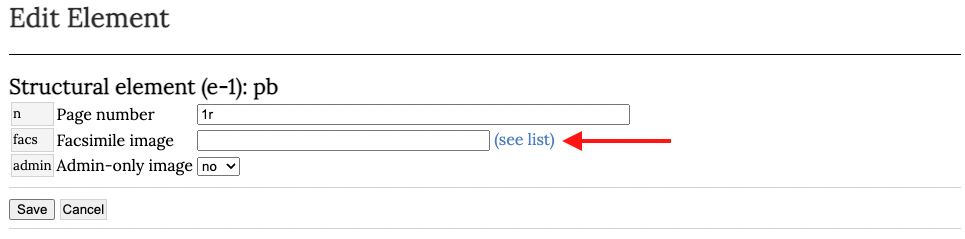
Para adjuntar el facsimil de cada página a nuestro documento vamos a pinchar en el botón que nos permite visualizar los cambios de página (<pb>). Inmediatamente después hacemos clic en el indicador de página [1r].
En la página de edición que se abrirá vamos a pinchar en el enlace (see list) como se muestra a continuación:
Se abrirá una nueva pestaña en donde se podrán buscar y adjuntar archivos desde la computadora. Antes de iniciar esta acción se debe denominar el archivo con la secuencia estándar concebida para los facsímiles como se presentó anteriormente en este documento (en 1.1.1). Para ello, se debe pinchar en el botón Choisir un fichier, navegar hasta la ubicación del archivo y una vez seleccionado hacer clic en Save.

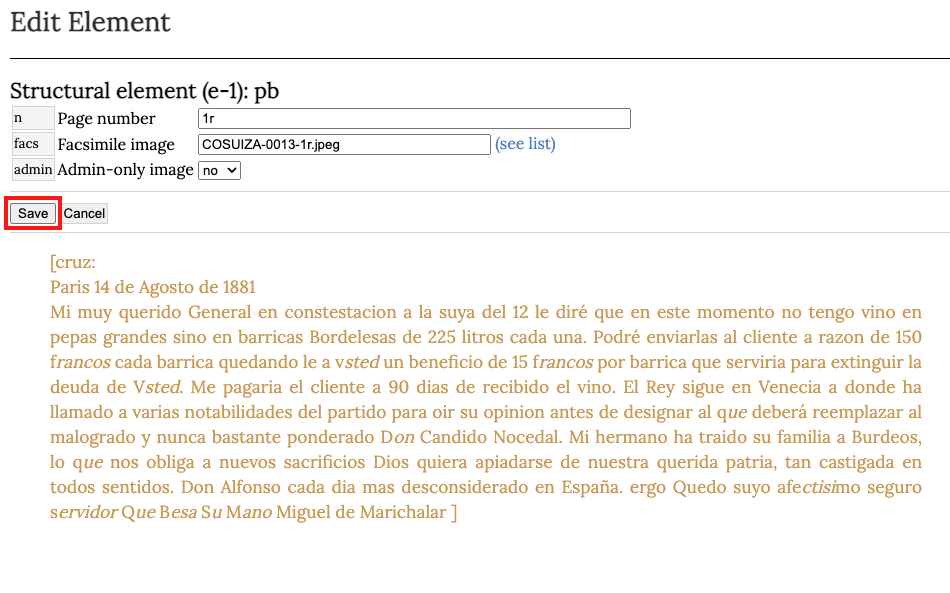
El archivo se habrá guardado en el directorio destinado a conservar los facsímiles en el servidor del COSUIZA. Ingresamos el nombre del archivo —incluida su extensión— al campo Facsimile image y hacemos clic en Save.
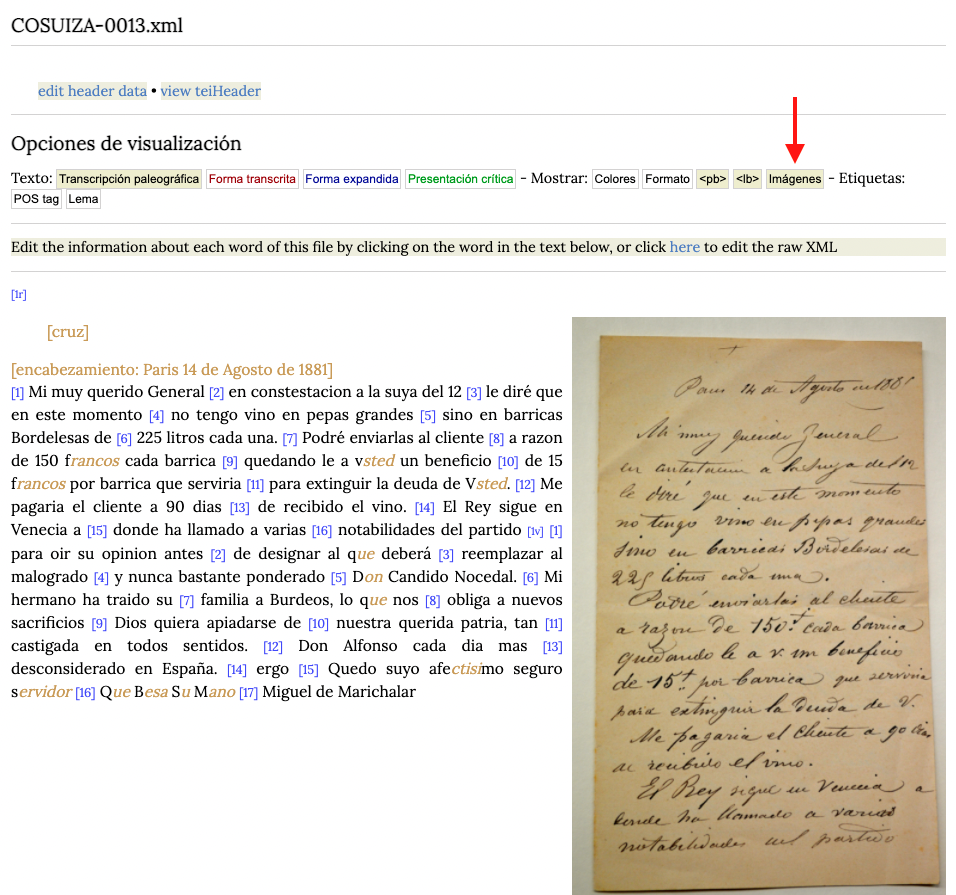
Terminada esta etapa, podremos ir a la página de visualización de nuestro documento y el botón Imágenes nos permitirá visualizar el facsímil.
Cabecera
En este apartado vamos a agregar la cabecera de nuestro documento. Comenzaremos instalando el editor de código fuente Visual Studio Code. Tras instalar y abrir el programa, vamos a pinchar en la pestaña de las extensiones como se muestra en la siguiente figura:
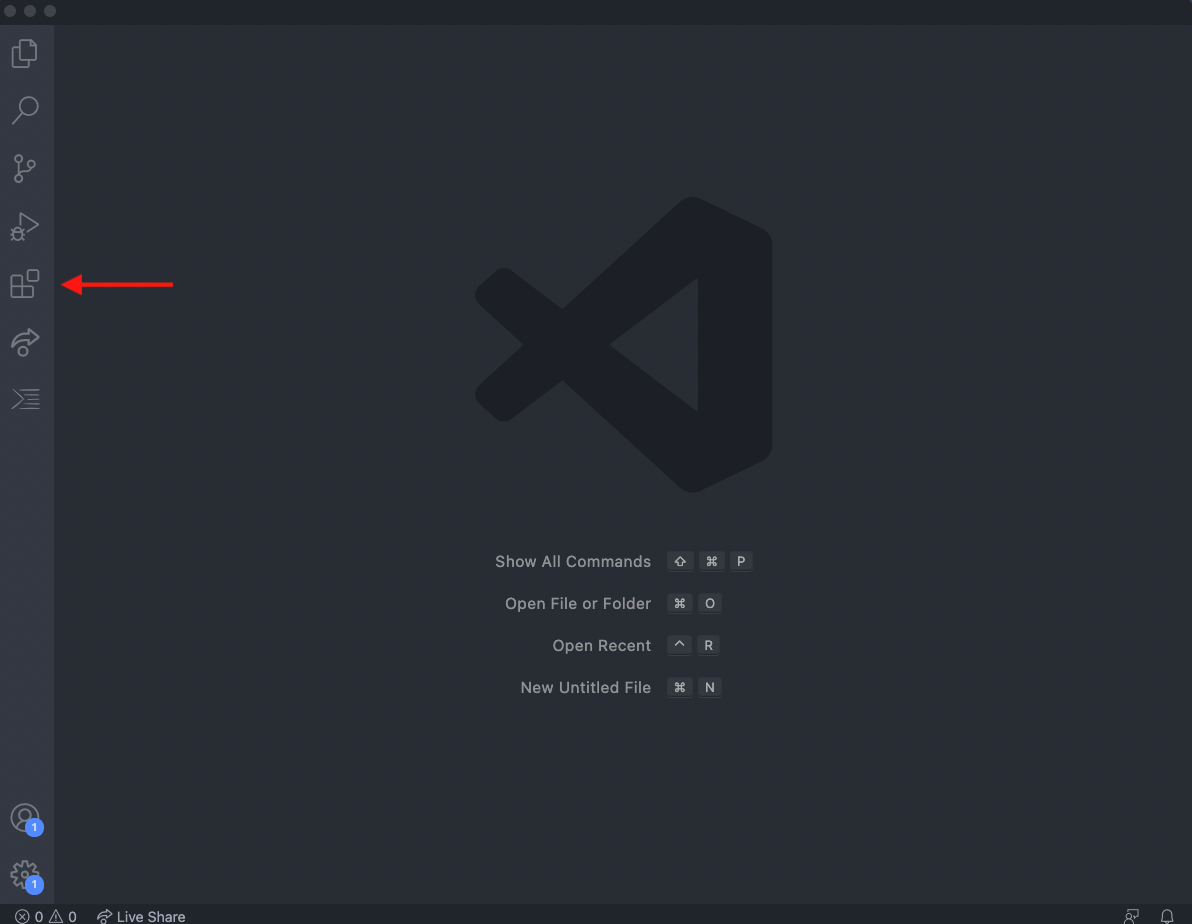
Vamos a escribir xml en el cuadro de texto y vamos a pinchar en el botón install. Esta extensión nos ayudará a comprobar que nuestra cabecera está bien estructurada.
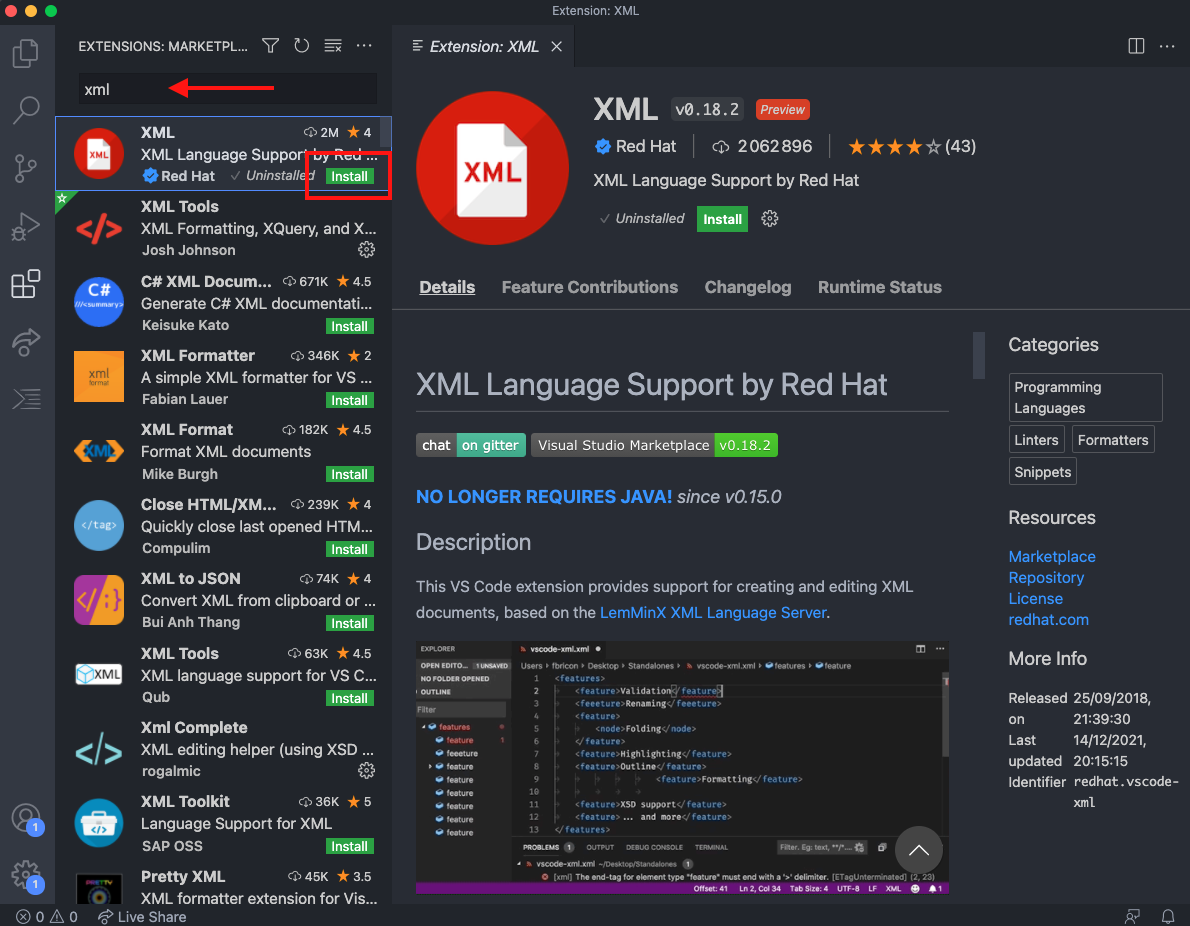
Luego, vamos a abrir nuestra cabecera con la ayuda de este editor de código fuente. Primero, pincha en este enlace. La carpeta que se descargará contiene dos documentos XML, uno es la cabecera que usaremos para completar los datos correspondientes a nuestro documento y el otro es el mismo, sin embargo, todos los campos llevan comentarios para recordar la finalidad de cada etiqueta. Vamos a abrir la carpeta que hemos descargado en nuestro editor de código fuente como vemos en la figura debajo, o simplemente arrastrando la carpeta sobre el icono de Visual Studio Code.
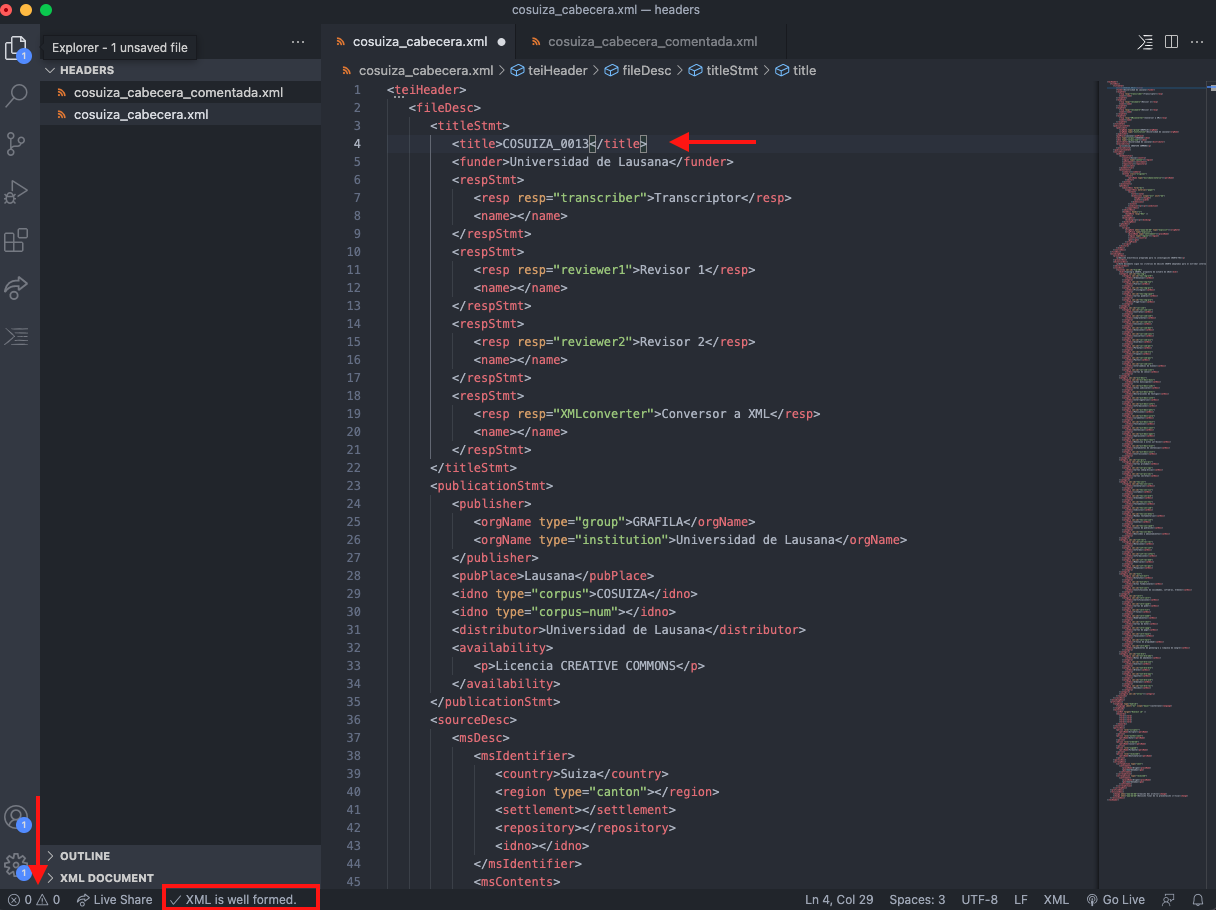
Una vez abierto el archivo XML podemos agregar los datos directamente en nuestro editor de código. En la figura debajo podemos ver que dentro de la etiqueta <teiHeader> hemos completado con COSUIZA-0013, el nombre de archivo de nuestra carta. En la parte inferior izquierda se indica la cantidad de errores existentes en el archivo y, en la barra inferior, aparece la información respecto a la validez del archivo. En nuestro caso, nuestro archivo es válido.
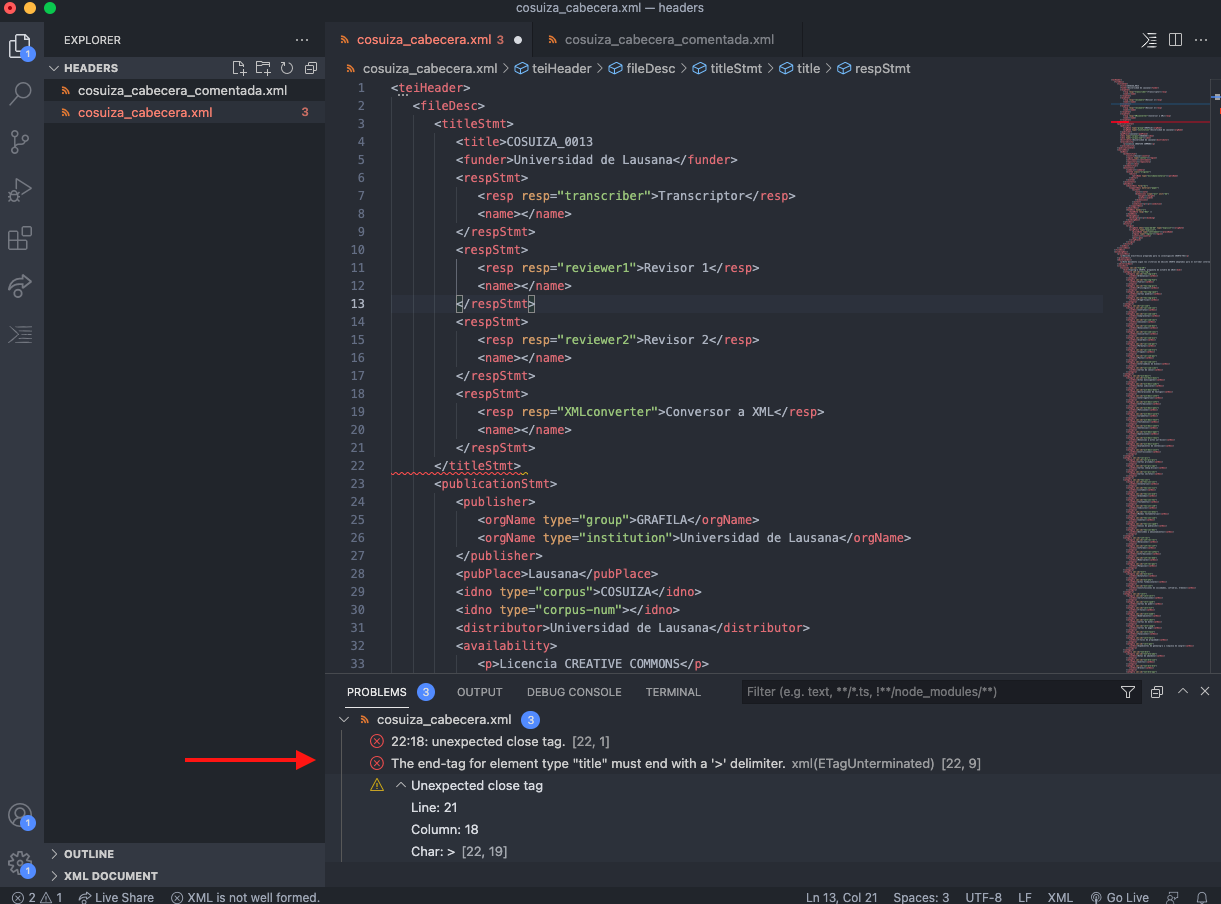
En el caso de existir errores, estos aparecen señalados en la parte inferior. En la figura debajo, a nuestro elemento <title> le falta la etiqueta de cierre.
Después de haber agregado todos los datos pertinentes, vamos a copiar el texto de nuestra cabecera en el portapapeles y vamos a ir a nuestro documento en el COSUIZA.
Vamos a pinchar en la opción que nos permite visualizar el archivo XML sin formato como se muestra en la figura debajo:
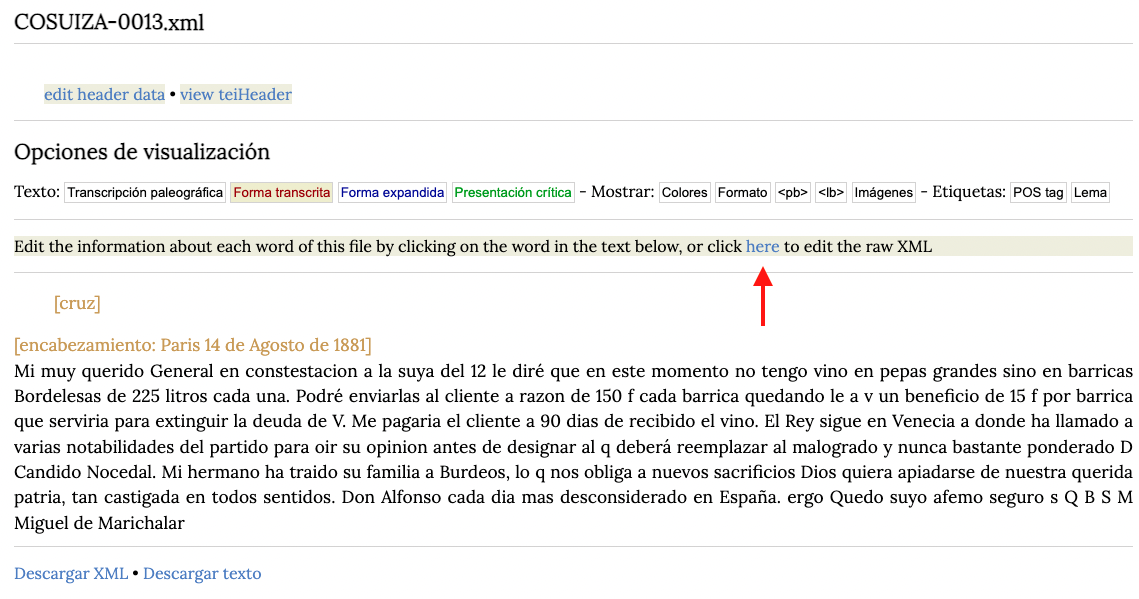
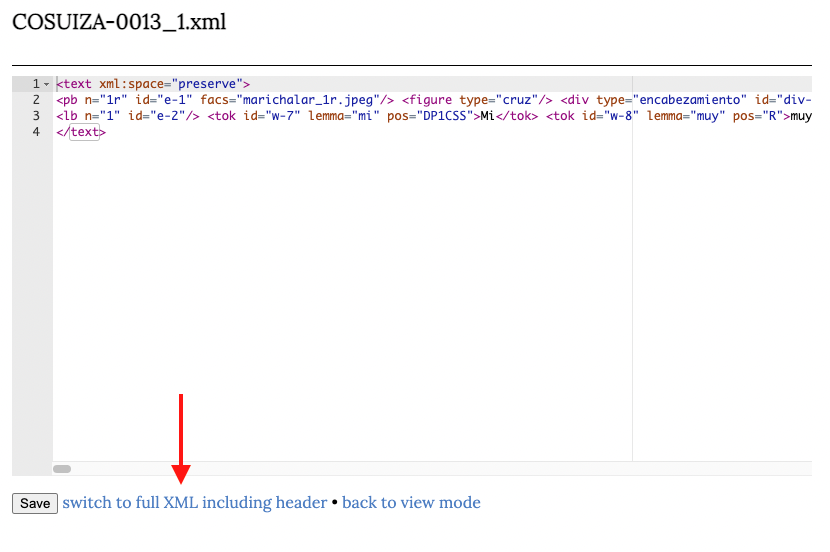
Después pinchamos en el enlace Switch to full XML including header como vemos a cotinuación:
En seguida podremos ver el elemento <teiHeader> que se constituye automáticamente al crear un archivo en Teitok. No obstante, no contiene la información ni la estructura de nuestra cabecera presentada en el apartado de los § metadatos.
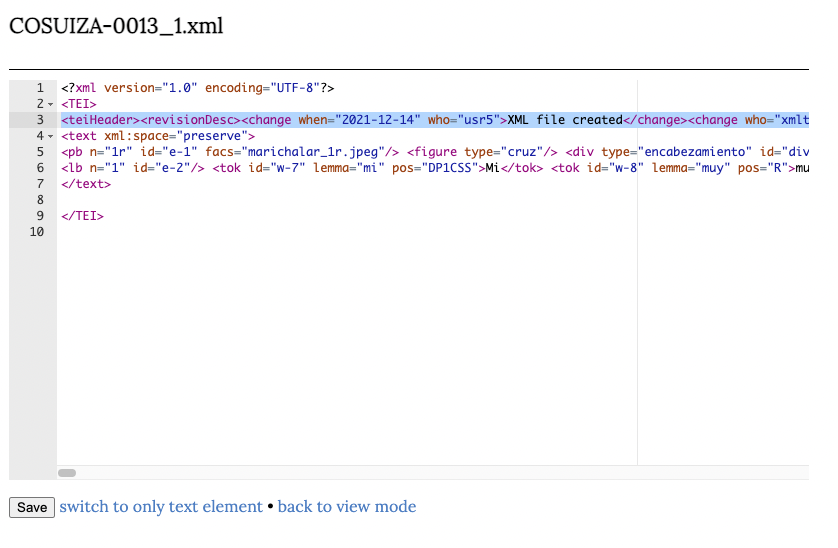

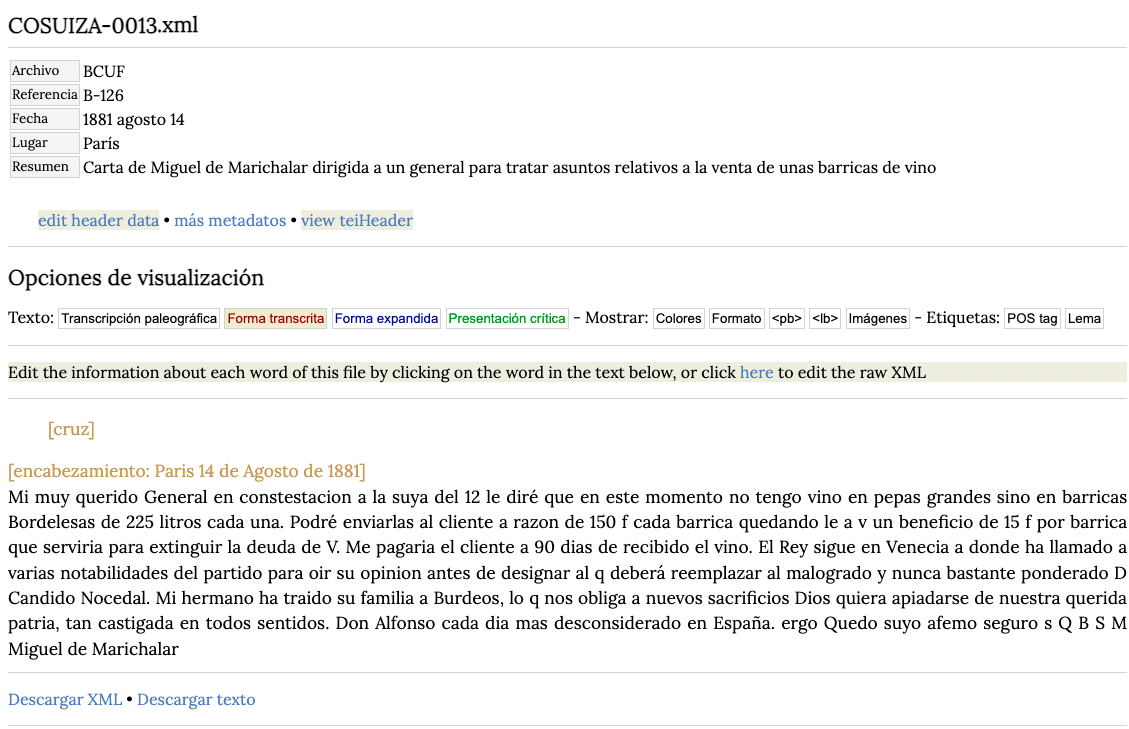
Al volver a nuestra página de visualización de nuestro documento podemos ver en la parte superior los metadatos pertinentes.
Videotutorial
Acceso
Creación de archivo XML y tokenización
Edición de token
Puntuación
Unión y separación irregular de palabras
Etiquetado morfosintáctico y lematización
Facsímil